| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

Implementing Artificial Neural Network Training Process in PythonANN learning has been successfully used to learn real-valued, discrete-valued, or vector-valued functions including issues like different types of features landscapes, speech recognition, and learning robot control techniques. ANN learning is resistant to errors in the training data. The discovery that biological to such are composed of extremely intricate webs of densely interconnected in brains served as inspiration for the development of artificial neural networks (ANNs). A tightly connected network of around 1011-1012 neurons make up the human brain. A neural network is composed of connected I/O units, each of which has a weight corresponding to one of its computer programmes. You can use big databases to develop predictive models. The human nervous system serves as a foundation for this model. You can use it to do human learning, computer speech, picture interpretation, and other tasks. A paradigm for information processing that draws inspiration from the brain is called an artificial neural network (ANN). ANNs learn via imitation just like people do. Through a learning process, an ANN is tailored for a particular purpose, including such pattern classification or data classification. The synapses connections which exist here between neurons change as a result of learning. 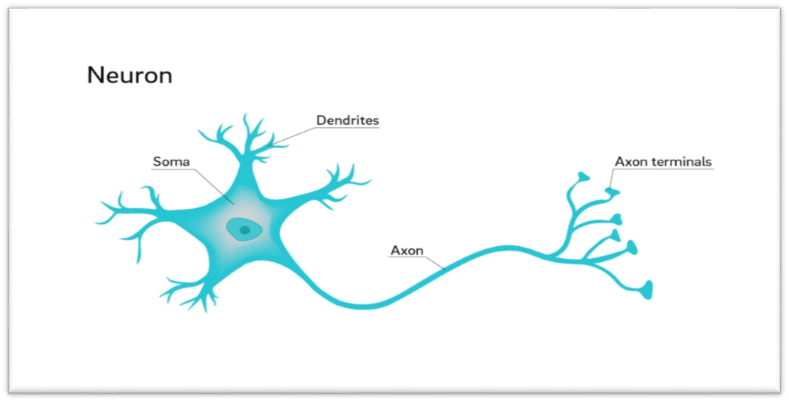
There are hundreds of billions more neurons in the human brain. These neurons are joined by synapses, which are nothing more than the points at which one neuron can communicate with another neuron via an impulse. The excitatory signal that one neuron provides to another neuron is joined to all of the inputs of the that neuron. The target neuron will fire a action signal forward if it reaches a certain threshold; this is the way the thinking process operates inside. By utilising matrices to build "networks" on a computer, computer scientists may simulate this process. These networks can be viewed as an abstract of neurons without taking into account all the biological complexity. We will just model a two-layer NN that can solve a linear classification issue in order to keep things simple. 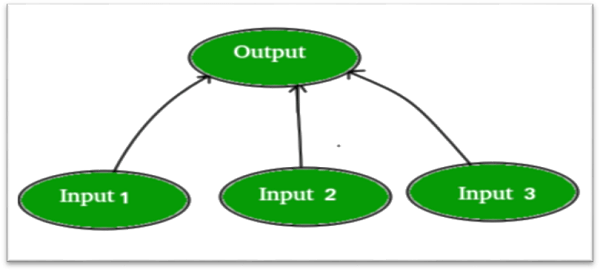
As an example, let's imagine you have a problem wherein we wish to predict an output given a collection of inputs and outputs. 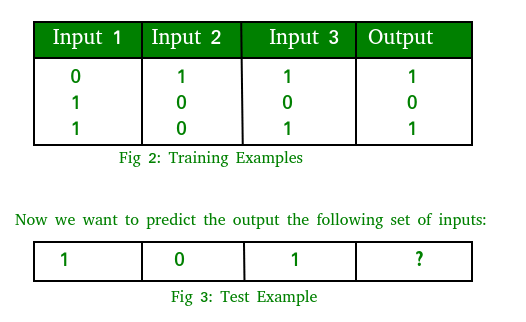
Keep in mind that the third column's values, which are what our output is in each training example in Figure 2, are directly tied to the output. Therefore, the output result is for test example should be 1. Following Steps make up Training Process
The input information is fed forward through the network, as the name suggests. Each hidden layer receives the data input, processes it in accordance with the activation function, and then transfers it to the following layer. The input should only be supplied in a forward direction in order to produce some output. During output generation, the data must not flow in the other direction because that would create a cycle and prevent the output from ever being formed. Feed-forward networks are those with such arrangements. The feed-forward network aids in the spread of information. multiplying the weights by the inputs (just use random numbers as weights) Suppose Y = WiIi = W1I1 + W2I2 + W3I3. To determine the neuron's output, run the result via a sigmoid algorithm. The result is normalised between 0 and 1 using the sigmoid function: 1/1 + e-y. Each hidden and output layer node experiences pre activation and activation during forward propagation.
Determine the error, or the discrepancy between the output that was produced and what was anticipated. Depending on the mistake, change the weight by multiplying the mistake by the input, and gradient of a Sigmoid curve, and the error once again. The foundation of network training is backpropagation. It is a technique for adjusting a neural network's weights based on the rate recorded in the previous period (i.e., iteration). By properly tweaking the weights, you may lower error rates and improve the model's reliability by broadening its applicability. The term "backward propagation of errors" is shortened to "backpropagation" in neural networks. It is a common technique for developing artificial neural networks. With regard to each weight in the network, this technique aids in taking the derivative of a loss function. For several thousand iterations, repeat the entire process. Let's write the entire procedure in Python code. We will use the NumPy library so make all of the matrices calculations simple for us. To run the code, you would need to install the numpy library one our computer. 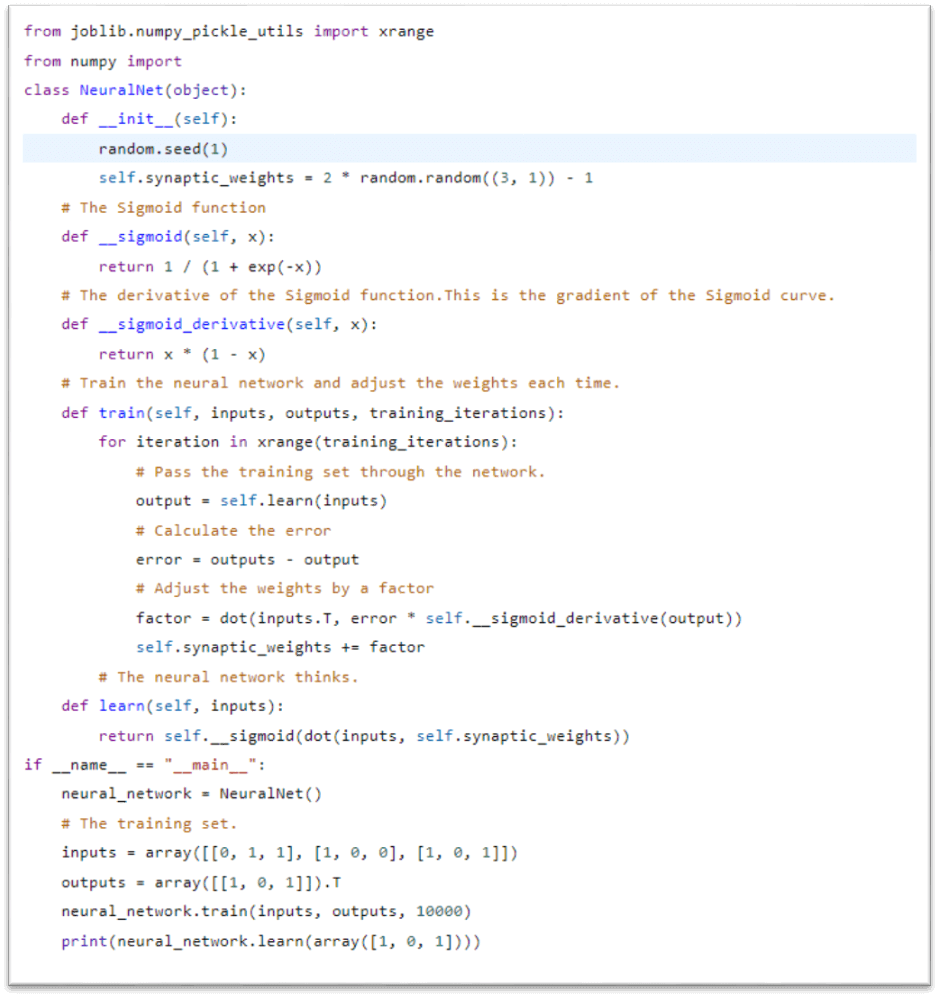
Output Our neural network expects the result to be 0.65980921 after 10 iterations. It doesn't look good because the correct response should be 1. We get 0.87680541 if we extend the iterations to 100. A smarter network is emerging! Following that, after 10000 iterations, we have 0.9897704, which is slightly closer and indeed a decent result.
Next TopicPrivate Variables in Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








