| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

Outer join Spark dataframe with non-identical join columnApache Spark is a popular distributed computing framework for big data processing that offers a rich set of APIs for working with structured data. Spark provides a powerful way to work with data using data frames, which are like tables in a relational database. One of the important operations while working with data frames is to join them together. In Spark, we can join two data frames using different types of joins, including inner join, left join, right join, and outer join. In this article, we will focus on the outer join in Spark data frames when the join columns are non-identical. Spark data frames provide a way to organize and manipulate data in a structured way similar to a table in a relational database. Spark data frames are highly optimized for distributed computing and provide a rich set of APIs for data manipulation, transformation, and analysis. One of the key operations in Spark data frames is joining. Joining allows us to combine two or more data frames based on a common column, which is similar to the SQL join operation. Spark data frames support several types of joins, including inner join, outer join, left join, and right join. One approach to perform an outer join on non-identical join columns is to rename the columns in one of the data frames. We can use the withColumnRenamed() method to rename the columns as shown in the previous example. Before diving into the outer join operation, let us first understand what a join operation in Spark is. A join operation in Spark data frames is a way to combine two data frames based on a common column. Spark supports different types of join operations, such as inner join, left join, right join, and outer join. In an outer join operation, all the rows from both data frames are included in the output. If a row does not have a matching record in the other data frame, then the values for that row in the other data frame are filled with null values. However, when the join column is non-identical in both data frames, we need to take some additional steps to perform the outer join operation. Let's consider an example to understand the outer join operation in Spark data frames with non-identical join columns. Suppose we have two data frames, "sales" and "customer," as shown below The "sales" data frame contains information about the sales made by different customers, including the customer ID, product ID, and the amount of the sale. The "customer" data frame contains information about the customers, including their ID, name, and city. To perform an outer join operation on these two data frames, we need to have a common column that we can use to join the two data frames. However, in this case, the join column is non-identical in both data frames. The "sales" data frame has the customer ID column, while the "customer" data frame has the ID column. To perform the outer join operation, we can rename the columns in one of the data frames to make them identical. For example, we can rename the "ID" column in the "customer" data frame to "customerID" using the withColumnRenamed() method: Now, we can perform the outer join operation using the join() method and specifying the join type as "outer": In the above code, we first specify the join condition as sales.customerID == customer.customerID, which specifies that we want to join the two data frames based on the customer ID column. We then specify the join type as "outer" to perform the outer join operation. The resulting data frame will contain all the rows from both data frames, and the values for the non-matching rows will be filled with null values. We can further process the resulting data frame to remove any null values or perform any other operations as needed. Implementation:Syntax of join() function Parameters: other: DataFrame. Right side of the join on : str, list or Column, optional. A list of column names, a join expression (Column). how : str, optional standard inner Inner, cross, outer, full, fullouter, full outer, left, leftouter, left outer, right, rightouter, right outer, semi, leftsemi, left semi, anti, leftanti, and left anti are the only options that can be used. Dataframes Used for Outer Join and Merge Join Columns in PySpark We will generate two sample data frames with non-identical join columns to demonstrate the idea of outer join and merging join columns in PySpark data frames. We can see that "Name" serves as both the first data frame's join column and the second data frame's join column. The values in the join column are also not the same. 
Outer Join using the Join functionWe'll utilise PySpark's "join" function to conduct an outer join on the two DataFrame. The two DataFrames and the join column name are both accepted as inputs by the "join" function. All the rows from both DataFrames are returned by the outer join operation together with any matching rows. The appropriate columns for non-matching rows will have null values. Output: Here, we can see that "dataframe1" and "dataframe2" have been combined on the outside, and where there is no data, "null" has been provided. The resulting DataFrame contains every column from both DataFrames. 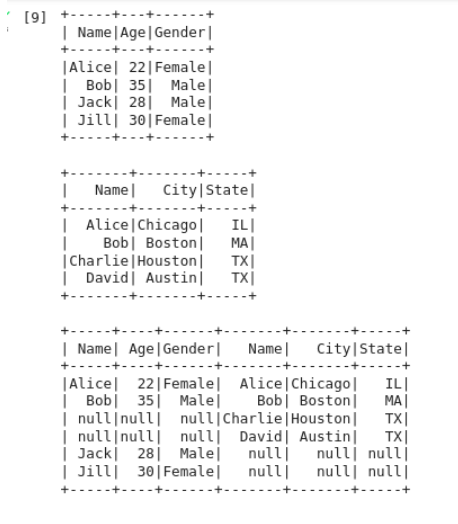
With a few minor adjustments, we will now use one column for our Name column to improve readability. If you want both columns, follow the instructions above. Output: 
Merge Using Outer JoinIn PySpark, the merge method is not accessible. Nonetheless, Pandas have access to it. You can convert your PySpark data frames to Pandas data frames, merge them using the merge technique, and then convert the merged Pandas data frame back to a PySpark data frame if you're working with tiny data sets and wish to use the merge method. An outer join is a type of database join that allows us to combine two tables while keeping all the rows from one or both tables, even if there is no corresponding match in the other table. In Python, we can perform an outer join using the merge() function from the pandas library. Let's consider an example where we have two tables, employees, and departments, with the following data: To perform an outer join between these two tables based on the department_id column, we can use the merge() function as follows: The how parameter specifies the type of join we want to perform. In this case, we specify 'outer' to perform an outer join. The on parameter specifies the column to join on. The resulting merged table will look like this: id_x name_x salary department_id id_y name_y 0 1.0 Alice 50000.0 1.0 1.0 Sales 1 2.0 Bob 60000.0 2.0 2.0 Marketing 2 3.0 Charlie 70000.0 2.0 2.0 Marketing 3 4.0 Dave 80000.0 3.0 3.0 Engineering 4 5.0 Eve 90000.0 3.0 3.0 Engineering 5 NaN NaN NaN 4.0 NaN NaN Note that the id_x, name_x columns are from the employees table and the id_y, name_y columns are from the departments table. Since there is no employee with a department_id of 4, the last row contains NaN values. An outer join using merge() allows us to combine two tables while keeping all the rows from one or both tables, even if there is no corresponding match in the other table. In conclusion, the outer join operation in Spark data frames is a powerful way to combine data from two different sources based on a common column. When the join columns are non-identical in both data frames, we can use the withColumnRenamed() method to rename one of the columns and perform the outer join operation as usual. With Spark data frames, we can efficiently process large amounts of data and perform complex data operations with ease.
Next TopicPhotogrammetry with Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








