| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

Find_Elements_by_Xpath() using Selenium PythonSelenium is basically a powerful tool for automating web browsers and testing web applications. It provides a wide range of methods and techniques to interact with web elements. One of the most commonly used methods is find_elements_by_xpath(). This method allows you to locate elements on a web page using XPath expressions. Understanding XPathThe language known as XPath can be used to browse both HTML and XML texts. It enables you to provide a path to elements depending on their characteristics, structure, or content. As a result, it is an effective tool for finding elements on a webpage. XPath expressions can be absolute or relative. An absolute XPath expression starts from the root of the document, while a relative XPath expression starts from the current node. Relative XPaths are generally preferred as they are more flexible and less likely to break when the structure of the webpage changes. Install Selenium:Open your terminal or command prompt and run the following command to install the Selenium package: This command will download and install the Selenium package along with its dependencies. 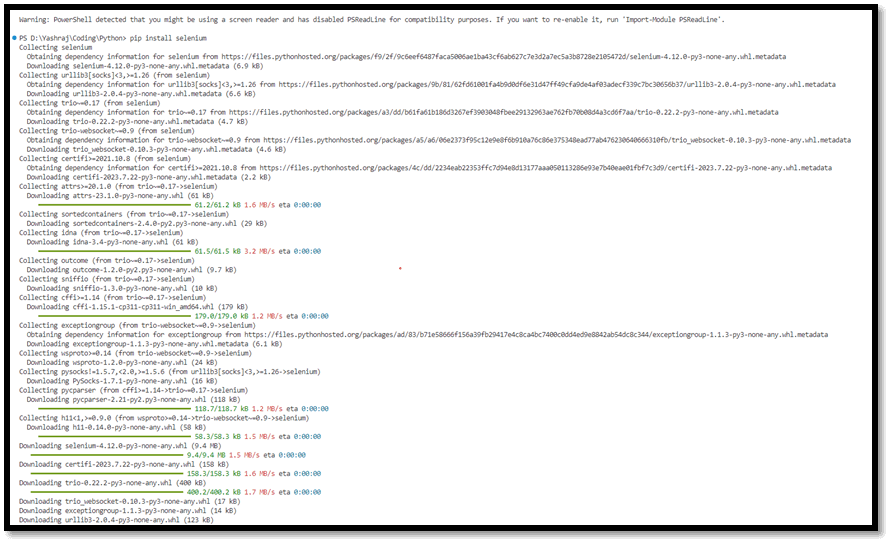
Install lxml:Syntax: 
Examples1) Using tag name:Python Code: Browser Output: 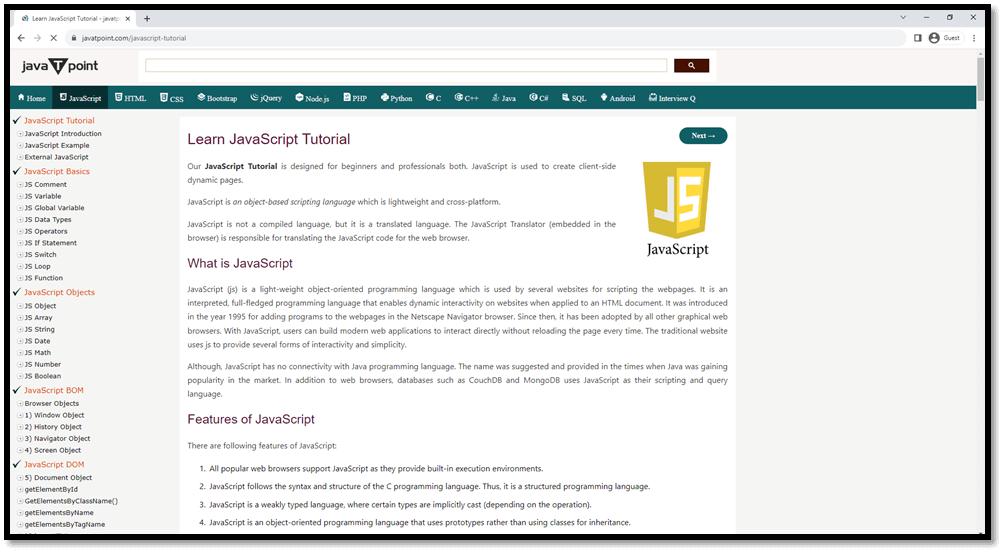
Terminal Output: 
2) Using class name:Python Code: Browser Output: 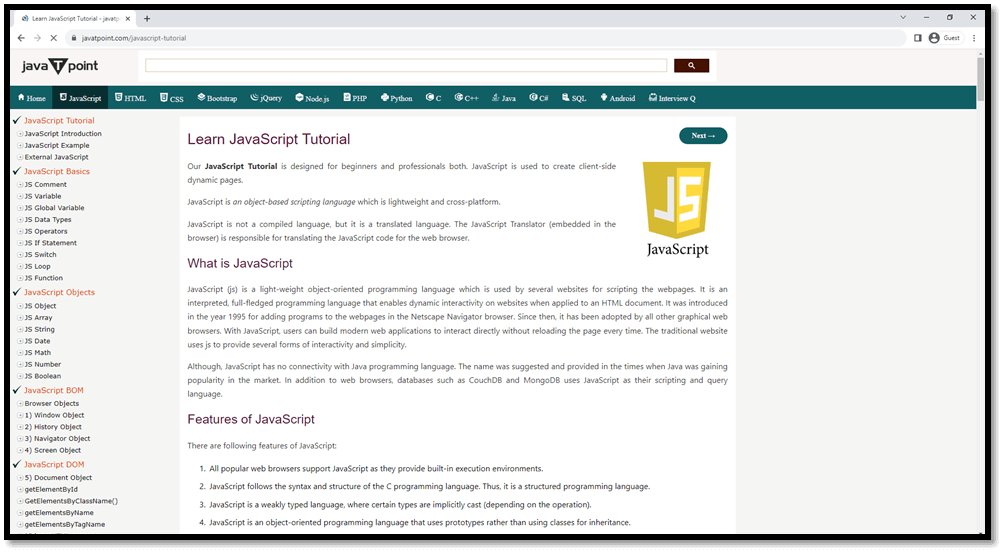
Terminal Output: 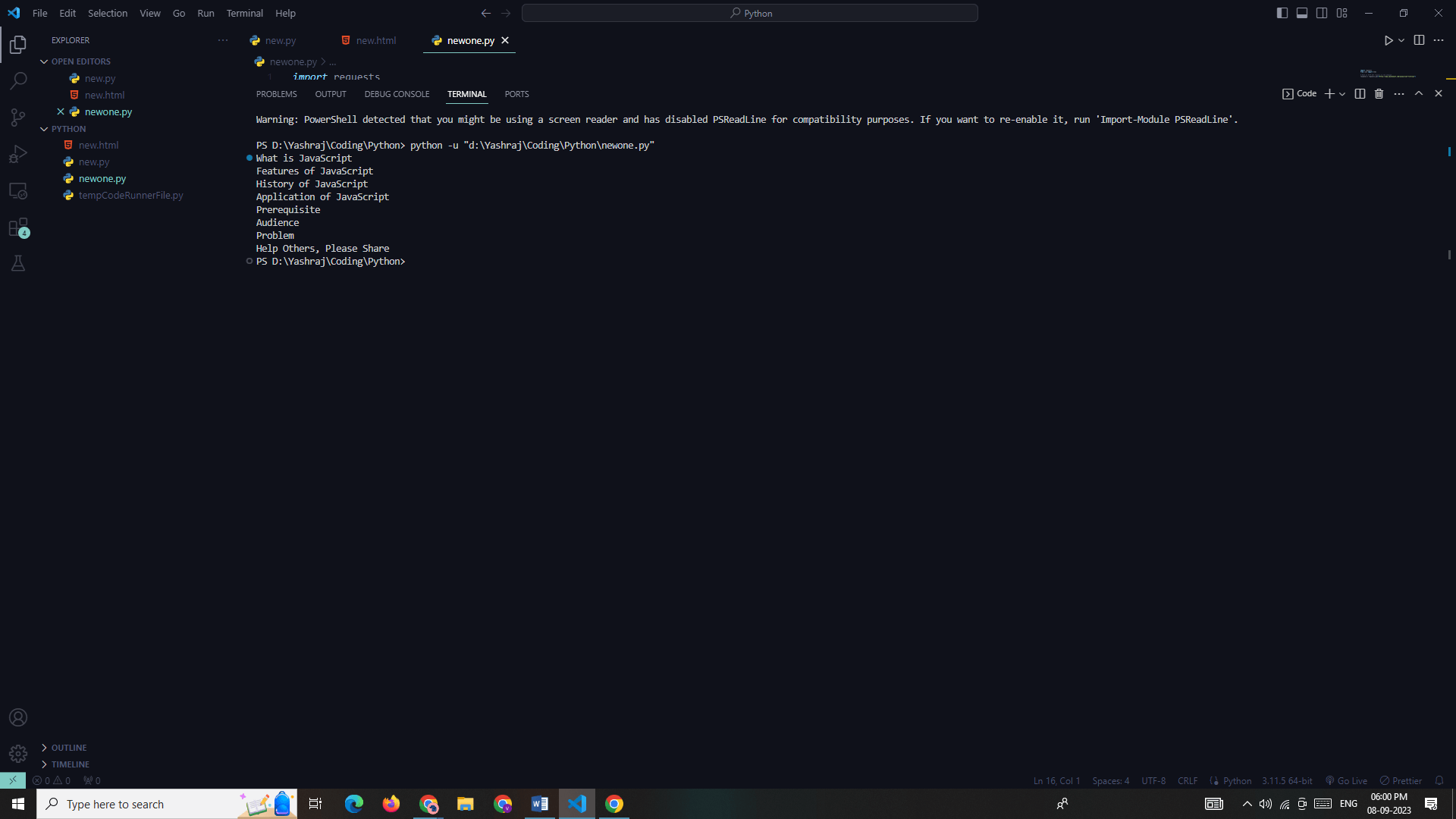
Advantages of XPath:1. Powerful and Flexible: XPath allows you to select complex and precise elements. It can navigate the entire structure of an XML or HTML document, enabling you to target elements based on various criteria. 2. Location Strategies: XPath provides multiple location strategies, allowing you to select elements by tag name, attribute value, text content, position, and more. This versatility makes it a valuable tool for locating elements in different scenarios. 3. Traversal and Relationships: The document tree can be navigated using XPath in both ways (up and down). As a result, you can choose elements based on how they are related to other elements, such as parent, child, sibling, etc. 4. Relative XPaths: Relative XPaths are not tied to the absolute structure of the document, which makes them more robust to changes in the page structure. This is crucial for maintaining automation scripts in dynamic web environments. 5. Support for Attributes: XPath allows you to target elements based on their attributes (e.g., id, class, name, etc.), providing a powerful mechanism for element identification. 6. Wide Applicability: XPath is not limited to web scraping or automation. It is also widely used in other domains like XML parsing, data extraction, and transformation. Disadvantages of XPath:1. Complexity: XPath expressions can become complex, especially for intricate selections. This can lead to longer and potentially harder to maintain-XPath queries. 2. Performance Impact: Poorly constructed XPath queries can lead to slower performance, especially when used in scenarios where elements are numerous or deeply nested. 3. Browser Dependency: XPath expressions can behave differently in different browsers. What works in one browser may not work as expected in another, so it's essential to test your XPath expressions across different browsers. 4. Learning Curve: Understanding the syntax and best practices for XPath can be challenging for individuals who are just getting started. Being skilled could require some time and practice. 5. Not Ideal for Dynamic Content: XPath is less suitable for dynamically generated content or situations where elements may change attributes or structure after page load, as it may lead to brittle selectors. 6. Limited to DOM Structure: XPath is designed for selecting elements within the Document Object Model (DOM). It may not be suitable for tasks that involve non-DOM elements or actions (e.g., handling JavaScript alerts). ConclusionUsing find_elements_by_xpath() with Selenium in Python provides a powerful way to locate and interact with elements on a webpage. By understanding XPath syntax and applying it effectively, you can automate a wide range of tasks in web testing and scraping. Remember to use relative XPaths whenever possible, as they are more robust to changes in the webpage structure. Additionally, consider using waits to ensure that the elements you're looking for are present before interacting with them. With the knowledge of XPath and Selenium, you're equipped to automate web interactions and efficiently test web applications.
Next TopicBack Driver Method - Selenium Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








