| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

Q-Learning in PythonReinforcement learning is a model in the Learning Process in which a learning agent develops, over time and in the best way possible within a particular environment, by engaging continuously with the surroundings. During the journey of learning, the agent will encounter different scenarios in the surroundings it's in. They are known as states. The agent in the state can select from a variety of permissible actions, which can result in various rewards (or punishments). The agent who is learning over time develops the ability to maximize these rewards to perform optimally in any condition it is in. Q-Learning is a fundamental type of reinforcement learning that utilizes Q-values (also known as action values) to improve the learner's behaviour continuously.
With all the knowledge needed, let's use an example. We will utilize the gym environment created by OpenAI to build the Q-Learning algorithm. Install gym: We can install gym, by using the following command: Before beginning with this example, we will need an helper code to see the process algorithm. Two helper files need to be downloaded from our working directory. Step 1: Import all the required libraries and modules. Step 2: We will instantiate our environment. Step 3: We have to create and initialize the Q-table to 0. Step 4: We will build the Q-Learning Model. Step 5: We will train the model. Step 6: At last, we will Plot important statistics. Output: 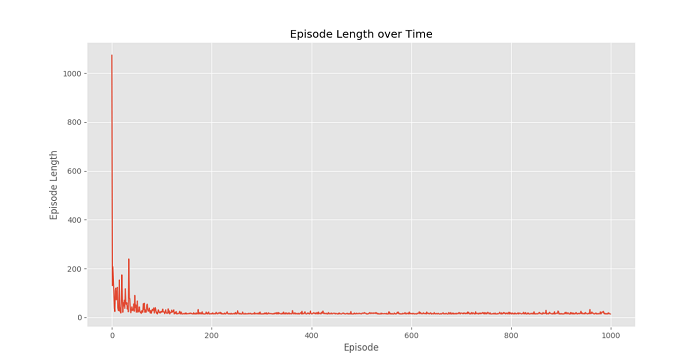
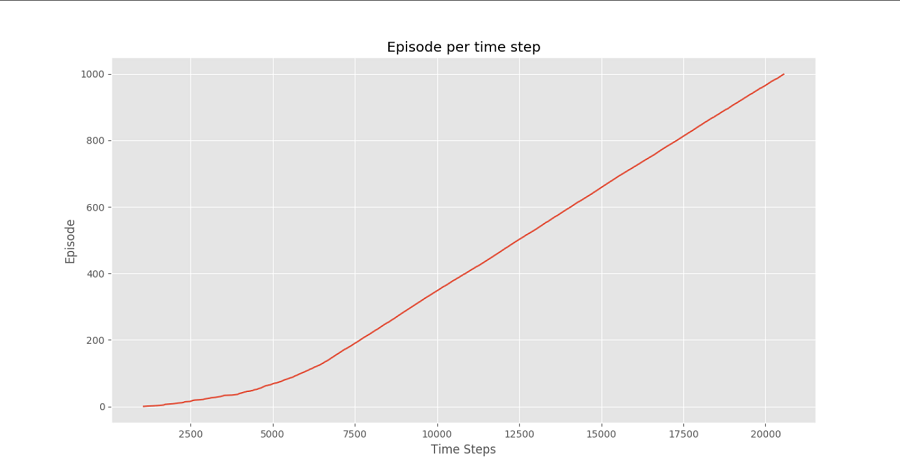
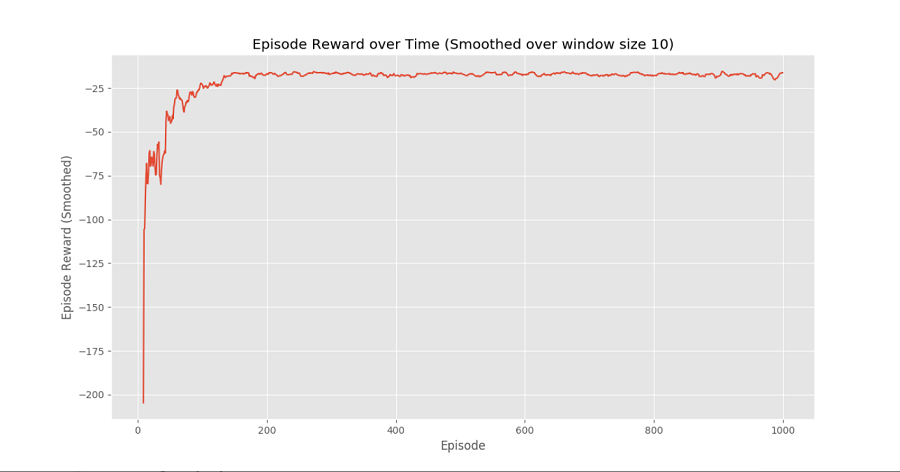
ConclusionWe can see in the Episode Reward Over Time plot that the rewards for each episode are gradually increasing in time until it gets to a point at a high reward per episode, which suggests that this agent learned to maximize the total reward in each episode by exhibiting optimal behaviour in each and every level.
Next TopicCombinatoric Iterators in Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








