| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

How does Tokenizing Text, Sentence, Words Works?Natural Language Processing (NLP) is an area of computer science, along with artificial intelligence, information engineering, and human-computer interaction. The focus of this field is computers can be programmed for processing and analysing huge quantities of data from natural languages. It's not easy to do since the process of understanding and reading languages is much more intricate than appears at first. Tokenization is the process of breaking a text string into an array of tokens. The users can think of tokens as distinct parts like a word can be a token in the sentence, while the sentence is a token within the form of a paragraph. The Key Elements of this Tutorial:
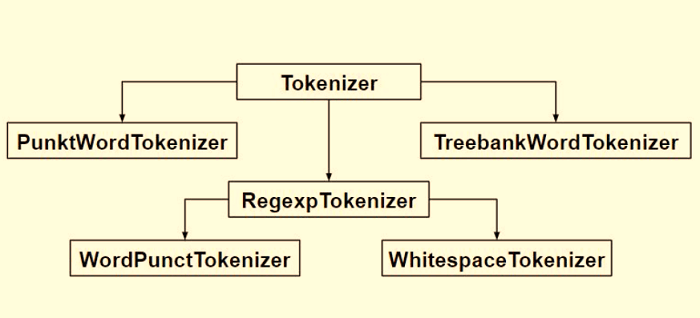
Sentence TokenizationSentence Tokenization is use for splitting the sentences in the paragraph Code 1: Output: ['Hello everyone.', 'Welcome to Javatpoint.', 'We are studying NLP Tutorial'] How "sent_tokenize" Works?The sent_tokenize function use the PunktSentenceTokenizer instance from the nltk.tokenize.punkt module, which is trained already and therefore it is very well known for marking the beginning and end of sentence at the characters and punctuation. PunktSentenceTokenizer -PunktSentenceTokenizer is mostly used for small data, cause it's hard for it to deal with massive amount of data. Code 2: Output: ['Hello everyone.', 'Welcome to Javatpoint.', 'We are studying NLP Tutorial'] Tokenize sentence of different languageWe can tokenize the sentence in various languages by using pickle file of any other language than English. Code 3: Output: ['Hola a todos.', 'Bienvenido a JavatPoint.', 'Estamos estudiando PNL Tutorial'] Word TokenizationWord Tokenization is used for splitting the words in a sentence. Code 4: Output: ['Hello', 'everyone', '.', 'Welcome', 'to', 'Javatpoint', '.', 'We', 'are', 'studying', 'NLP', 'Tutorial'] How "word_tokenize" Works?The word_tokenize() function is basically the wrapper function which is used for calling the tokenize() function that is an instance of the TreebankWordTokenizer class. Using TreebankWordTokenizerCode 5: Output: ['Hello', 'everyone.', 'Welcome', 'to', 'Javatpoint.', 'We', 'are', 'studying', 'NLP', 'Tutorial'] These tokenizers operate by separating the words by punctuation and spaces. This allows the user to choose how to deal with punctuations during processing. As we can see in the outputs of the code above, it doesn't eliminate punctuation. PunktWordTokenizerPunktWordTokenizer does not separates the punctuation from the words. Code 6: Output: ['Let', "'s", 'see', 'how', 'it', "'s", 'working', '.'] WordPunctTokenizerWordPunctTokenizer is used for separating the punctuation from the words. Code 7: Output: ['Hello', 'everyone', '.', 'Welcome', 'to', 'Javatpoint', '.', 'We', 'are', 'studying', 'NLP', 'Tutorial'] Using Regular ExpressionCode 8: Output: ['Hello', 'everyone', 'Welcome', 'to', 'Javatpoint', 'We', 'are', 'studying', 'NLP', 'Tutorial'] Conclusion:In this tutorial, we have discussed different functions and modules of the NLTK library for tokenizing the sentence and words of English as well as different languages using the pickle method. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








