| |

Make Python Program Faster using ConcurrencyIn this tutorial, we will learn about the concurrency and how to speed up Python program using concurrency. We will understand how concurrency methods compare with the asyncio module. We will also discuss what parallelism is and some of the concurrency methods. What is Concurrency?The concurrency is known as simultaneous occurrence. The things that are occurring simultaneous are known as different names such as thread, task, and process. However, at a high-level, they all refer to a sequence of instruction that run in order. It is possible to halt each process or thought at specific moments, allowing the processor, whether it is a CPU, to transition to another task. The progress of each process is saved to enable resumption from the exact point where it was stopped. One may question the reason behind Python's usage of distinct terminologies for representing similar concepts. However, upon closer examination, it becomes apparent that threads, tasks, and processes share similarities only when observed at a broad level. When delving into specifics, each concept embodies slight distinctions. As you advance through the examples, you will gain a better understanding of their dissimilarities. Now, let's focus on the "simultaneous" aspect of the definition. However, it is important to be cautious as, upon closer inspection, only multiprocessing actually executes these streams of thought concurrently. Threading and asyncio operate on a single processor, and thus, only one process runs at a time. However, they cleverly take turns to enhance the overall performance, even though they do not execute multiple trains of thought simultaneously. Despite this, we still refer to this as concurrency. What is Parallelism?Parallelism in Python is the ability to execute multiple tasks or processes simultaneously. It involves using multiple processors, either on a single machine or distributed across a network, to perform tasks in parallel, thus increasing overall processing speed and efficiency. Parallelism can be achieved through multiprocessing or multithreading, and it is often used for computationally intensive tasks such as scientific computing, machine learning, and data analysis. Python creates new processes with multiprocessing. A process can be considered a separate program in its own right, although it is typically described as a group of resources such as memory and file handles. One analogy is to view each process as operating in its own independent Python interpreter. As each train of thought in a multiprocessing program operates as a distinct process, they can run on separate cores, enabling them to execute truly concurrently, which is advantageous. Although this approach may have some complexities, Python handles them effectively. When is Concurrency Useful?Concurrency can helpful in the two problems which are known as CPU-bound and I/O-bound. I/O-bound problems can lead to sluggish program performance as it often needs to wait for input/output (I/O) from external sources. Such problems are common when the program operates with slower resources than the CPU. 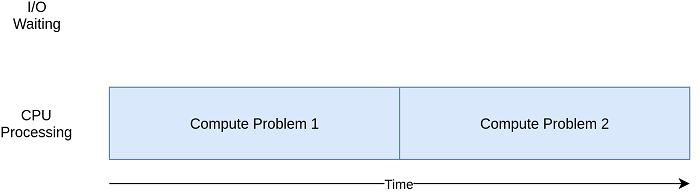
Let's see the difference between I/O-Bound Process and CPU-Bound Process.
How to Speed Up an I/O-Bound ProgramIn this section, we will see the I/O-bound programs and a common problem. We are taking an example of downloading content over the network. Synchronous VersionWe will start with a non-concurrent version of the task. We will use the requests module. Example - The program is concise, as demonstrated by the download_all_sites_from_network() function, which downloads contents from a URL and displays its size. Notably, a Session object from the requests module is utilized. Although the get() function from the requests module could be used directly, creating a Session object unlocks advanced networking capabilities that significantly enhance performance. The function download_all_sites() establishes a Session and then iterates through a list of websites, downloading them one by one. Upon completion, it displays the duration of the process, allowing you to appreciate the degree of concurrency achieved in the following examples. Advantage of Synchronous Version One of the major advantages of this code version is its simplicity. It was relatively effortless to develop and troubleshoot and was also more comprehensible. The code follows a linear flow of logic, which makes it easier to anticipate the subsequent step and its expected behavior Disadvantage of Synchronous Version The main disadvantage of the synchronous version is its slowness compared to other solutions. Although being slower may sometimes be a minor problem, adding Concurrency may not be necessary if the program runs infrequently and only takes 2 seconds to complete with a synchronous version. However, if the program is executed frequently or takes several hours to finish, it becomes crucial to explore Concurrency. Therefore, let's proceed by modifying this program using threading. Threading VersionWe will write the above program using the threading. Let's see the following example. This version utilizes threading to improve the download speed of multiple sites. The download_all_sites function now uses a ThreadPoolExecutor to create a pool of threads to execute the download_site() function. The max_workers parameter specifies the maximum number of threads to use. The get_session() function creates a requests. The session object for each thread ensures that each thread has its own session. The program downloads 80 copies of the same website and measures the time to complete the task. Finally, it prints out the total number of sites downloaded and the duration of the process. The ThreadPoolExecuter can be broken down into Thread + Pool + Executor. We know about the threaded part. The pool creates a pool of threads, and each can work concurrently. And the Executor part is responsible for how the thread in the pool will run. It will execute the request in the pool. Fortunately, the standard library includes ThreadPoolExecutor as a context manager. You can use syntax to handle the creation and release of the thread pool. When we have the ThreadPoolExecutor, we can use the map() method. This method executes the passed-in function on each site in the list. The beauty of it is that the function is automatically executed concurrently by the thread pool it manages. Another notable modification in our example is that each thread must create requests.Session() instance. While examining the requests documentation, it may take time to be apparent, but after reviewing this issue, it becomes evident that a special session is required for each thread. One of the fascinating and challenging aspects of threading is that since the operating system controls when a task is interrupted and another task begins, any data shared between threads must be protected and made thread-safe. However, it is unfortunate that requests.Session() is not inherently thread-safe. There are multiple approaches to ensuring thread safety of data access, depending on the data and its usage. One of these strategies involves using thread-safe data structures, such as Python's Queue module. Another viable strategy to employ in this scenario is called thread-local storage. By utilizing threading.local(), an object is created that resembles a global object but is unique to each thread. This approach is applied in your example through thread_local and get_session(). The local() function is provided in the threading module to specifically address this issue. Although it may appear unusual, you only need to create one instance of this object, rather than one for each thread. The object itself handles segregating data access from different threads to distinct data. Upon invoking get_session(), the session it retrieves is unique to the thread that is currently executing. Thus, every thread will generate a single session on its first invocation of get_session(), and subsequently employ that session for all subsequent calls during its lifecycle. Advantage of using thread The advantage of a thread is that it is fast. When we run the above program, we get the following output. Output - Downloaded 80 in 0.010993480682373047 seconds Disadvantages of using thread Interactions between threads can be intricate and challenging to identify. Such interactions can lead to race conditions, which often produce haphazard, sporadic bugs that can be particularly challenging to locate. If you are unfamiliar with race conditions, please read the section below for additional information. Asyncio VersionBefore diving deep into the asyncio, let's understand how asyncio works. At its core, asyncio revolves around a single Python object, the event loop, which manages how and when each task is executed. The event loop knows of every task and understands its current state. Although there are several potential states that tasks can be in, let's consider a simplified event loop that only has two states for now. The ready state means that a task is ready to be run and has work to do, and the waiting state means that a task is waiting for an external operation, such as a network call, to complete. The event loop selects a ready task and executes it until it finishes or reaches a waiting state. The task then relinquishes control to the event loop, which selects another ready task to execute. After a running task yields control to the event loop, the event loop puts that task into either the ready or waiting list. Then, it checks all tasks on the waiting list to determine if they have become ready due to an I/O operation being completed. The event loop knows the tasks in the ready list are still ready since they have not run yet. The event loop iterates over the waiting list to check if any tasks are ready to run. After all, tasks are sorted into the right list again; the event loop picks the next task to run based on its state. In this case, the simplified event loop picks the task that has been waiting for the longest and runs it. The process continues until the event loop has finished executing all tasks. In asyncio, tasks don't get interrupted in the middle of an operation and only give up control when they explicitly choose to do so. This property enables easier sharing of resources than in threading because thread safety is not a concern in asyncio. async and await The async keyword is used to define a coroutine function, which is a function that can be paused and resumed while it waits for an I/O operation to complete. The coroutine function returns a coroutine object, which represents the ongoing operation. The await keyword is used to wait for a coroutine to complete. When the await keyword is used inside a coroutine function, the function is paused until the awaited coroutine completes its operation. During this time, the event loop can continue to run other coroutines. Once the awaited coroutine completes, the paused function is resumed with the result of the coroutine operation. Using async and await allows developers to write asynchronous code much easier to read and maintain than traditional callback-based code. Instead of managing callback chains and error handling, coroutines can be written more linearly, making the code more readable and easier to reason about. Let's implement the above example using the async and await. Example - The above code may seem more complex than previous two. It has a similar structure but there's bit more work setting up the tasks than there was creating ThreadPoolExecutor. We can share the session across all the tasks, so the session is created here as a context manager. The tasks can share the session because they are all running on the same thread, and the task cannot be interrupted while the session is in a bad state. The given context manager generates a list of tasks using asyncio.ensure_future(), which is responsible for starting them. After generating all the tasks, the function utilizes asyncio.gather() to maintain the session context until all the tasks are executed. The threading code performs a comparable operation, but it is simplified using the ThreadPoolExecutor, which manages the specifics. At the moment, there is no AsyncioPoolExecutor class available. Asyncio has a notable advantage over threading in terms of scalability. Creating each asyncio task demands fewer resources and less time than a thread, enabling the creation and execution of multiple tasks with ease. In this example, each site is downloaded using a separate task, which is highly effective. Advantage of asyncio It is faster than the thread version. The scalability concern is also a significant factor in this scenario. Executing the threading example with a thread designated for each site leads to a noticeable decrease in speed compared to using only a few threads. Conversely, executing the asyncio example with hundreds of tasks does not impact its speed at all. Output - Downloaded 80 sites in 1.6838884353637695 seconds Disadvantage of asyncio At present, asyncio has a few concerns. To fully leverage the benefits of asyncio, you require specific async versions of libraries. If that requests were used to download the sites, the process would be significantly slower due to requests not being designed to inform the event loop that it is blocked. However, this issue is gradually becoming less problematic as more libraries embrace asyncio. Multiprocessing VersionThe multiprocessing version takes the full advantages of the multiple CPU. Let's understand the following example. Example - While the following code snippet is shorter than the one using asyncio, it bears resemblance to the example using threading. Before examining the code, let's explore the benefits of using multiprocessing. The multiprocessing module in the standard library aims to eliminate the limitation of running code on a single CPU by leveraging multiple CPUs. It achieves this by creating a new instance of the Python interpreter to execute on each CPU and assigning a portion of your program to execute on it. However, starting a new Python interpreter is a time-consuming process, unlike creating a new thread in the current interpreter. It is a resource-intensive operation that comes with some challenges and limitations, but it can significantly enhance performance for specific problems. Advantage of multiprocessing Version This example using the multiprocessing module is convenient to set up and does not require significant additional code. It is also highly efficient and utilizes the full potential of your computer's CPU power. Disadvantage of multiprocessing Version Compared to the previous examples, this version requires some additional setup, and the usage of a global session object may seem strange. It is essential to carefully consider which variables will be accessed in each process, which requires some thinking and planning. As we can clearly see that, it is slower than the asyncio version. Downloaded 80 in 11.359532356262207 seconds ConclusionThis tutorial included the basic type of Concurrency available in Python - threading, asyncio, and multiprocessing. With the knowledge gained from these examples, you can make informed decisions about which concurrency approach to employ for a specific problem or whether Concurrency is necessary. Moreover, you have developed a deeper comprehension of the issues that can arise using Concurrency.
Next TopicMethod Overriding in Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








