| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

How to Read Contents of PDF using OCR (Optical Character Recognition) in PythonPython is one of the most preferred programming languages in today's world. We can use it for analyzing the data, but data is not always available in the required format. In such cases, we can convert the format of the file from pdf, jpg to the text (.txt) format for analyzing the data in a better way. There are many libraries available to perform such tasks. We can use the PyPDF2 module of Python for performing the task of converting the .pdf file into text format. The major disadvantage we can face while using this module is the encoding scheme. The PDF document files can contain a variety of encodings such as Unicode, ASCII, UTF-8, and many more. Therefore, converting PDF files into text may result in loss of data because of encoding schema. In this tutorial, we will learn how to read the content of a PDF file and store it in a text (.txt) format by using "Optical Character Recognition" method. At first, we have to convert the pages of the PDF document file into images, and then, we will use OCR for reading the content from the image and storing it in the text (.txt) format file. Required Modules:We have to install the following modules using the given command for this tutorial:
(for this the user should have Microsoft Visual C++ 14.0, Get it with "Build Tools for Visual Studio": https://visualstudio.microsoft.com/downloads/) Part 1:The first part will deal with converting my PDF pages into image files. Each page of the PDF file will be stored as an image file, and the names of the images will be stored as: Part 2:The second part would deal with recognizing the text from the image files in sorting it into the text file in ".txt" format. Here, we will process the image files for converting them into text content. Once we have the text as a string variable, we can start processing the text (.txt) file. Such as, in many PFD files, we can see that when a line is complete, but the last word cannot be written entirely in the same line, then, a hyphen is added in the end, and the word is continued in the following line. For example: For such words, we will do a fundamental pre-processing for converting the hyphen and the following line into a full word. When we complete the pre-processing, this text will be sorted in a separate text file. Code:Output: Input PDF file: 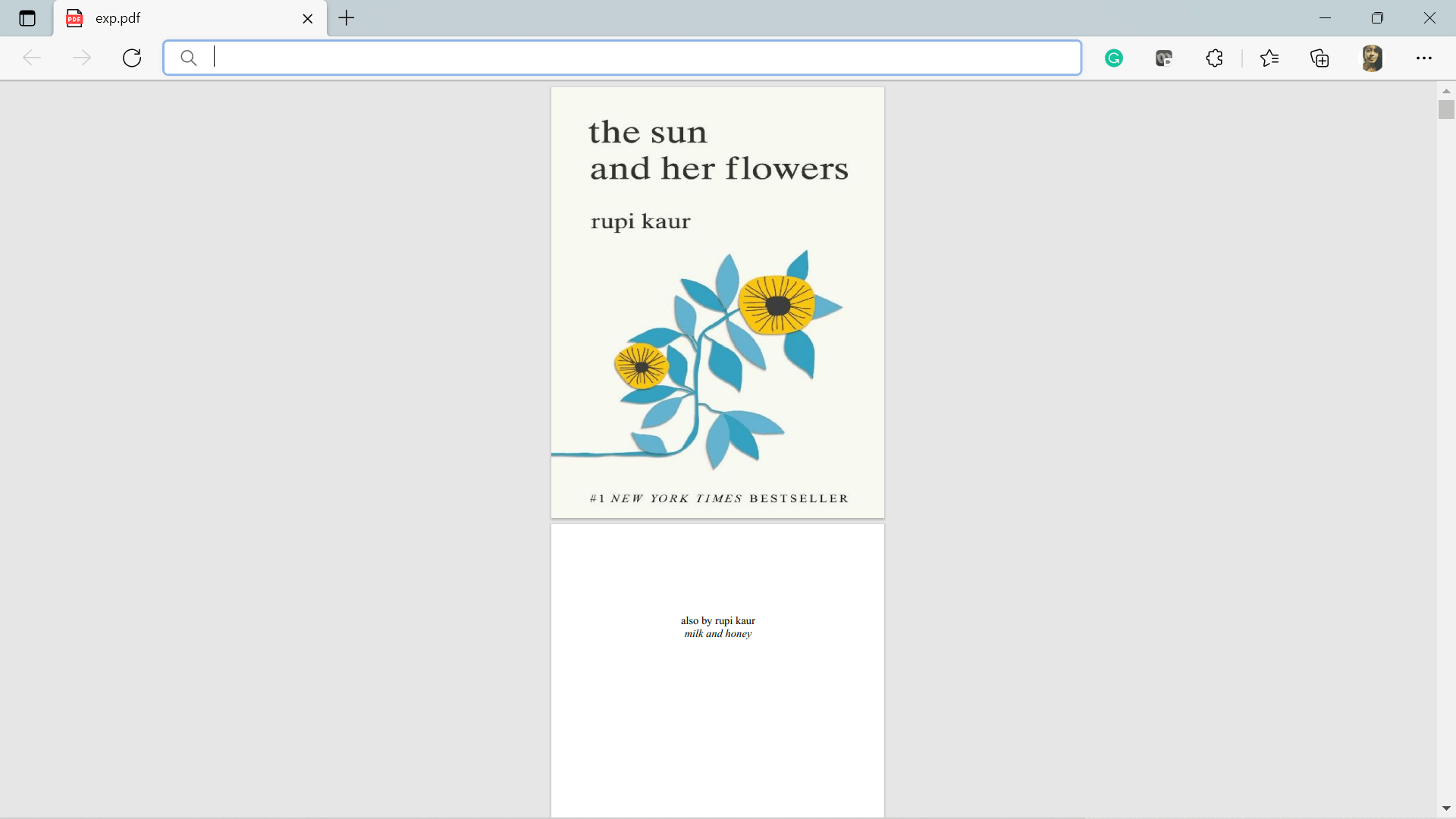
Output Text file: 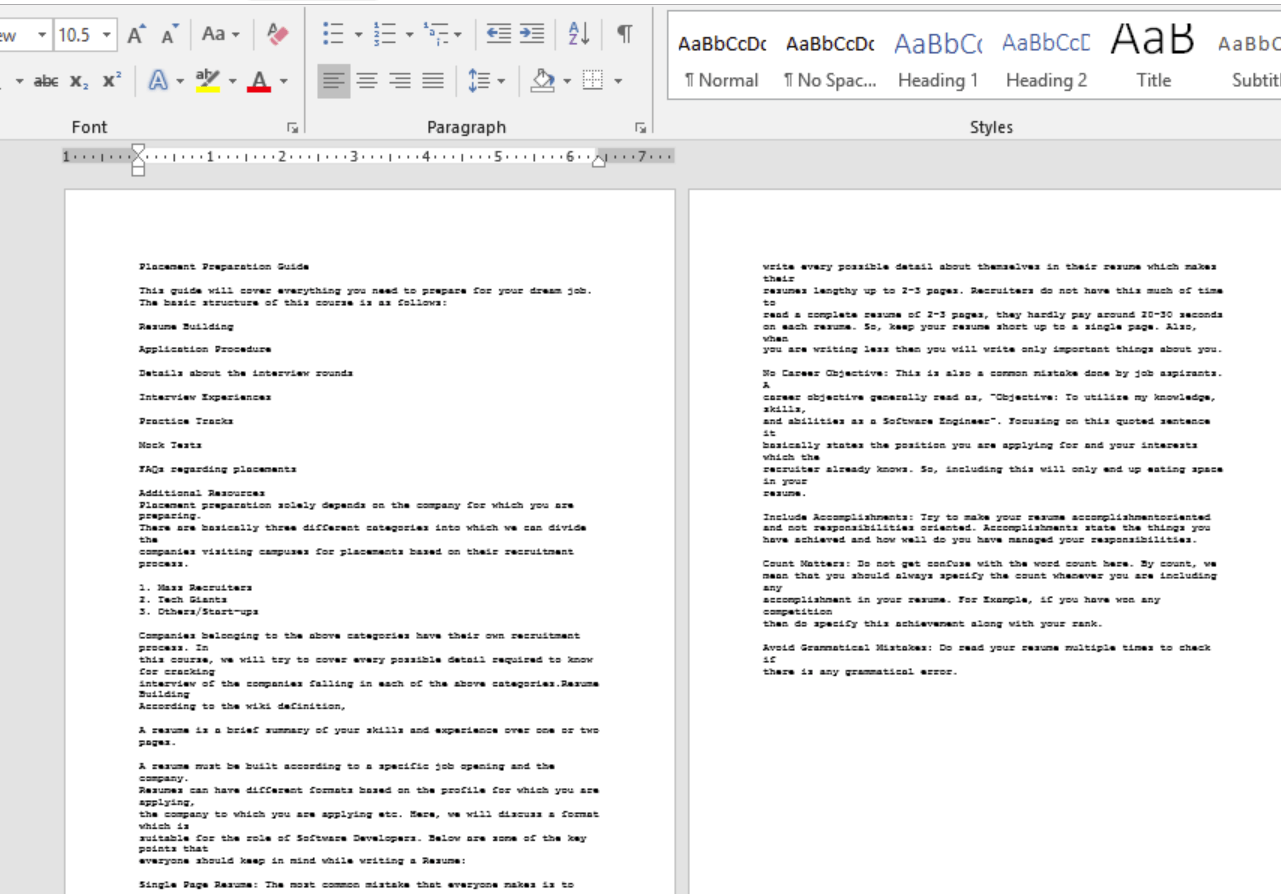
As we can see, the pages of the PDF file how converted into images. Then those images were read, and their content was written into a text file. Advantages of using OCR method:
Disadvantages of using OCR method:
ConclusionIn this tutorial, we have discussed how to read the PDF files' content by using OCR in Python.
Next TopicGrammar and Spell Checker in Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








