| |

How to get the First Match from a Python List or IterableYou might need to locate the first item in a Python iterable, like a list or dictionary, that meets a specific requirement at an indeterminate point in your Python trip. The sole exception is when it is necessary to confirm "that a" specific item is present in the iterable. You could need to locate a name in a list of names or a substring inside of a string, for instance. You're better off using the in-operator in these situations. But there are lots of situations when you might need to look for gear with certain features. As an illustration, you could have to:
This tutorial will cover the best approaches for each of the three scenarios. One option is to change your entire iterable to a new listing, then use it. Use index() to get the main item that meets your criteria: Output: 'Tiffany' Having utilised. Use Index() in this situation to discover that "Tiffany" is the first name in your listing with seven characters. This technique is not ideal, partly because you calculate the standard for every component even when the main item is a match. You are searching for a calculated characteristic of the devices you are iterating through within the constraints. This lesson will show you how to match such a derived attribute without doing unnecessary calculations. Learn how to get the First Match in a Python RecordYou might already be familiar with Python's operator, which can let you know if a product is part of an iterable. Even though that is the most efficient method for this purpose, you may occasionally need to match objects based on a calculated property of the objects, such as their lengths. For instance, interacting with a list of dictionaries, which is a typical outcome when processing JSON data, might be the case. Try the following information from country-Json: You might need to take control of the main dictionary, which is home to more than 100 million people. The in-operator is a poor choice for two reasons. To match it, you would need the entire dictionary, and it wouldn't return the same object instead of a Boolean value: Output: True There is no way to use it if you want to find the dictionary based on an aspect of the dictionary, like population. The usage of a simple for loop is probably the most understandable method to locate and manipulate the major component within the list based on a calculated value: Output: "nation": "Philippines," "inhabitants": 106651922 You can do whatever you want with the objective object inside the for-loop body rather than printing it. Make careful to end a loop once you're finished so you don't have to search the rest of the listing again. The first package, which you can obtain from PyPI, is straightforward and initially employs the for-loop approach. It provides a general-purpose function (). This function typically returns the initial true value from an iterable. The first true value is returned after the key argument has been passed through using an optional key parameter. Python Mills is Accustomed to Winning the Opening RoundPython interpreter to locate the primary element in a list or any other iterable, iterators are memory-efficient iterable. They are a fundamental feature of Python and are heavily utilized internally. Most likely, you've utilized turbines without even realizing it! Turbines have the potential drawback of being a little more concise and, as a result, not quite as readable as loops. Turbines do have some efficiency benefits, but these benefits might occasionally be insignificant when the importance of readability is considered. However, using them could be entertaining and level your Python game! There are several ways to create a generator in Python, but for this tutorial, you'll be using generator comprehensions: Output: 'nation': 'Canada,' 'inhabitants': 37057765 Once a generator iterator has been defined, you may call the subsequent() function on the generator to produce the nations one at a time until the list of nations is finished. You can modify the generator comprehension to include a conditional statement to ensure that the subsequent iterator only returns items that meet your criteria to locate the primary component in a list that matches a specific set of criteria. You use a conditional expression in the example below to produce items based on whether their population characteristic is greater than 100 million: Output: 'nation': 'Philippines,' 'inhabitants': 106651922 As a result, the dictionary generator will only now create dictionaries with a population attribute greater than 100 million. This implies that, like the for-loop method, the generator iterator's first call to next() will return the first item you're looking for in the list. A generator isn't exactly as pure as a for loop in terms of readability. Why then might you require one for this purpose? The next section will involve a quick performance comparison. Taking Mills and Loops' Efficiency into AccountAs always, while assessing efficacy, you shouldn't put too much stock in any one set of findings. Instead, create a test for your code using your own real-world experience before you make any crucial decisions. Additionally, it would help if you considered readability versus complexity; sometimes, saving a few milliseconds isn't worth it. You must develop a function for this test that can generate lists of any size with a certain value at a specific location: Output: ['country': 'Nowhere,' 'population': 10, 'country': 'Nowhere,' 'population': 10, 'country': 'Nowhere,' 'population': 10, 'country': 'Nowhere,' 'population': 10, 'country': 'Nowhere,' 'population': 10, 'country': 'Atlantis,' 'population': 100, 'country': 'Nowhere,' 'population': 10, 'country': 'Nowhere,' 'population': 10, 'country': 'Nowhere,' 'population': 10, 'country': 'Nowhere,' 'population': 10] The build list() function creates a list that is filled with things that are like one another. Except for one item, every item in the list is a duplicate of the fill argument. The worth argument, the lone outlier, is located on the index given by the at-position argument. To make the created listing more legible, you imported print and used it to output it. In any other case, the listing would always fit on a single line. With the help of this function, you can generate a sizable collection of lists that contain the objective value in various locations. This should be used to gauge how long it takes to find a part at the beginning and end of the list. To recognise a dictionary with a population characteristic more than fifty, you'll need two additional essential traits that are hard coded to look for loops and turbines: The features are hard-coded to keep things simple to examine. Making a reusable function is what you'll do in the next section. With these fundamental components in place, you can set up a script with time to check for matching characteristics with several lists that include the objective location and several locations inside the list: This script will produce the time it takes to find each component using the generator or the loop in two concurrent lists. The script may also generate a third listing with the target component in its proper location. Even while you should ideally map out your strategy, you are not acting on the findings. Try the following successful script, which utilizes matplotlib to provide a few charts from the output: Running the script may take some time, depending on the system you're using and the numbers you use for TIMEIT TIMES, LIST SIZE, and POSITION INCREMENT, but it should result in one chart showing the times plotted against one another: 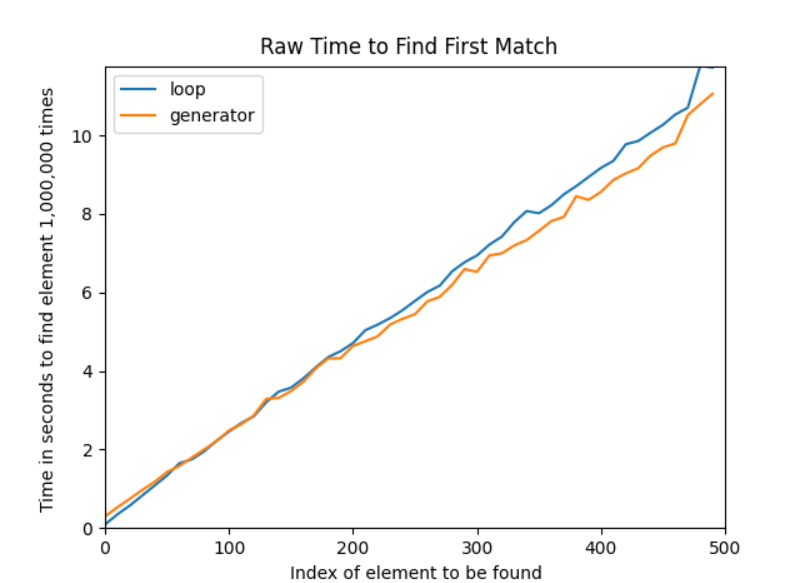
Additionally, after closing the main chart, you'll see another chart that displays the relative effectiveness of the two approaches: 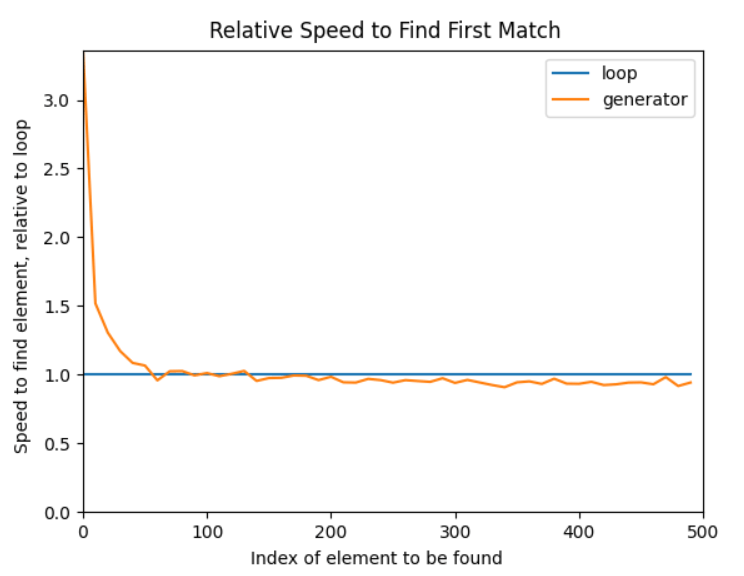
This final graph makes it abundantly evident that on this test, turbines are much slower than for loops when the desired item is close to the start of the iterator. Nevertheless, turbines outperform the for a loop quite consistently and by a significant amount once the component to find is at position 100 or higher: 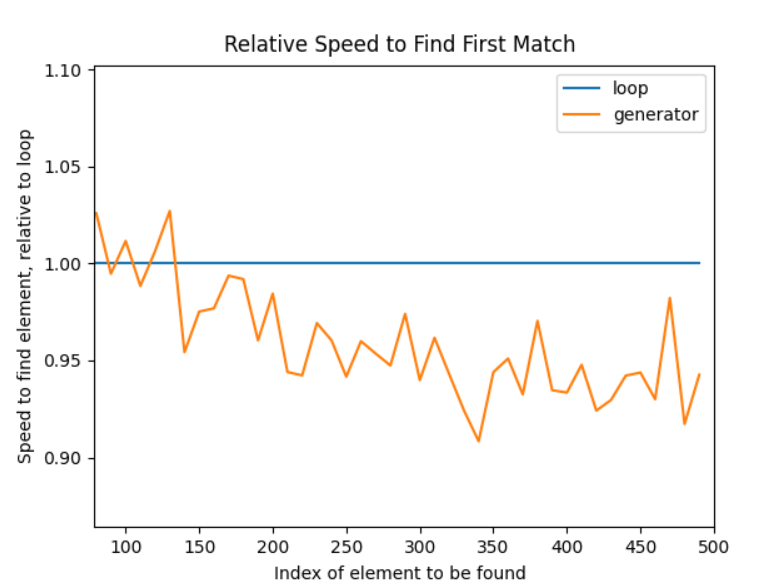
The magnifying glass icon on the preceding chart allows you to zoom in interactively. The chart is zoomed in to show an efficiency gain of about 5 or 6%. Although 5% is not particularly noteworthy, it is also not insignificant. The specific information you'll use and how regularly you should use it will determine whether it's worthwhile for you. With these results, you can hazard a guess that turbines are quicker than loops, even if turbines may be significantly slower when the object to be found is within the first hundred iterations. When using short lists, the difference in total raw milliseconds lost is negligible. But it's important to bear in mind for large iterations when a 5% gain can take minutes: 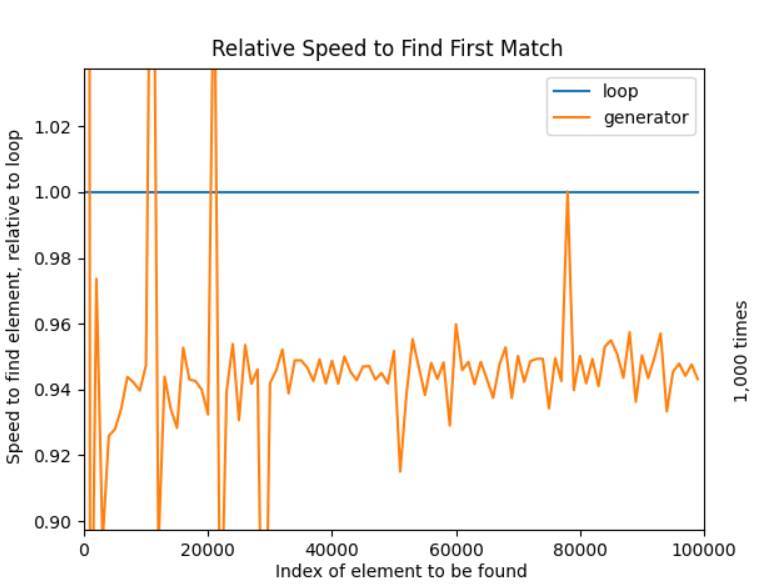
This final graph shows that the increase in efficiency stabilizes at about 6% for very large iterable. Don't worry about the spikes either; the TIMEIT TIMES was significantly lowered to test this large iterable. Creating Reusable Python Function to find the First MatchLet's say that you are thinking about fully optimizing your code because the iterable you foresee using will be on the large side. You'll utilize turbines in place of a for loop for that purpose. You'll also be working with a variety of totally distinct iterable using a variety of tools, so you'll need flexibility in how you combine, so you'll build your work to be able to achieve a variety of goals:
Even though there are many ways to do this, here is one using pattern matching: The function can have up to four arguments; depending on the combination of arguments you provide; it will behave differently. The value and main justifications form the foundation of the work's habits. As a result, the match assertion checks that the value is None and checks to see if the key is a function using the callable() function. For instance, if all the conditions are true, you submitted a key but no value. This means that the return value must be the first accurate outcome and that every item in the iterable needs to be passed through the key function. Another illustration: If all the match requirements are False, you have supplied a value but not a key. Passing a value without a key indicates that you are genuinely interested in the iterable primary component that matches the value you have passed. When the game is over, you receive your generator. The generator and the default argument for the first match must both be in the name of the function subsequent() before it can be used. You can look for matches using this function in the following four additional ways: Output: 'nation': 'Austria,' 'inhabitants': 8840521 Output: 'nation': 'Germany,' 'inhabitants': 82905782 Output: 'nation': 'Norway,' 'inhabitants': 5311916 Output: 'nation': 'Philippines,' 'inhabitants': 106651922 You have a lot of options in how to fit with this function. You could, for instance, deal with values, important features, or both! The operation signature in the first package mentioned earlier is only somewhat different. There is no worth parameter. By focusing on the essential variable, you can still achieve the same result as above: Output: 'nation': 'Cuba,' 'inhabitants': 11338138 You can even find a second implementation of get first() in the downloaded materials that match the signature of the first package: Whatever solution you choose, you now have a powerful, reusable function that can obtain the key items you require. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








