| |

BFS algorithmIn this article, we will discuss the BFS algorithm in the data structure. Breadth-first search is a graph traversal algorithm that starts traversing the graph from the root node and explores all the neighboring nodes. Then, it selects the nearest node and explores all the unexplored nodes. While using BFS for traversal, any node in the graph can be considered as the root node. There are many ways to traverse the graph, but among them, BFS is the most commonly used approach. It is a recursive algorithm to search all the vertices of a tree or graph data structure. BFS puts every vertex of the graph into two categories - visited and non-visited. It selects a single node in a graph and, after that, visits all the nodes adjacent to the selected node. Applications of BFS algorithmThe applications of breadth-first-algorithm are given as follows -
AlgorithmThe steps involved in the BFS algorithm to explore a graph are given as follows - Step 1: SET STATUS = 1 (ready state) for each node in G Step 2: Enqueue the starting node A and set its STATUS = 2 (waiting state) Step 3: Repeat Steps 4 and 5 until QUEUE is empty Step 4: Dequeue a node N. Process it and set its STATUS = 3 (processed state). Step 5: Enqueue all the neighbours of N that are in the ready state (whose STATUS = 1) and set their STATUS = 2 (waiting state) [END OF LOOP] Step 6: EXIT Example of BFS algorithmNow, let's understand the working of BFS algorithm by using an example. In the example given below, there is a directed graph having 7 vertices. 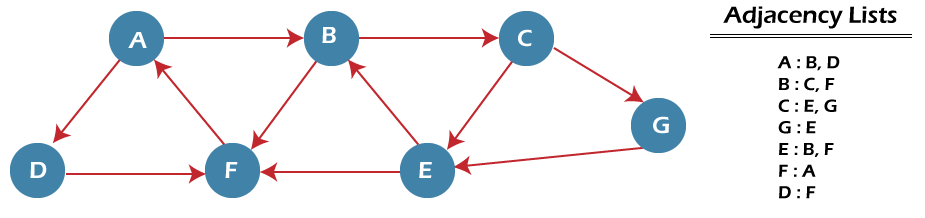
In the above graph, minimum path 'P' can be found by using the BFS that will start from Node A and end at Node E. The algorithm uses two queues, namely QUEUE1 and QUEUE2. QUEUE1 holds all the nodes that are to be processed, while QUEUE2 holds all the nodes that are processed and deleted from QUEUE1. Now, let's start examining the graph starting from Node A. Step 1 - First, add A to queue1 and NULL to queue2. Step 2 - Now, delete node A from queue1 and add it into queue2. Insert all neighbors of node A to queue1. Step 3 - Now, delete node B from queue1 and add it into queue2. Insert all neighbors of node B to queue1. Step 4 - Now, delete node D from queue1 and add it into queue2. Insert all neighbors of node D to queue1. The only neighbor of Node D is F since it is already inserted, so it will not be inserted again. Step 5 - Delete node C from queue1 and add it into queue2. Insert all neighbors of node C to queue1. Step 5 - Delete node F from queue1 and add it into queue2. Insert all neighbors of node F to queue1. Since all the neighbors of node F are already present, we will not insert them again. Step 6 - Delete node E from queue1. Since all of its neighbors have already been added, so we will not insert them again. Now, all the nodes are visited, and the target node E is encountered into queue2. Complexity of BFS algorithmTime complexity of BFS depends upon the data structure used to represent the graph. The time complexity of BFS algorithm is O(V+E), since in the worst case, BFS algorithm explores every node and edge. In a graph, the number of vertices is O(V), whereas the number of edges is O(E). The space complexity of BFS can be expressed as O(V), where V is the number of vertices. Implementation of BFS algorithmNow, let's see the implementation of BFS algorithm in java. In this code, we are using the adjacency list to represent our graph. Implementing the Breadth-First Search algorithm in Java makes it much easier to deal with the adjacency list since we only have to travel through the list of nodes attached to each node once the node is dequeued from the head (or start) of the queue. In this example, the graph that we are using to demonstrate the code is given as follows - 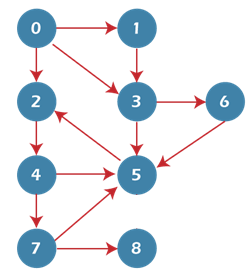
Output 
ConclusionIn this article, we have discussed the Breadth-first search technique along with its example, complexity, and implementation in java programming language. Here, we have also seen the real-life applications of BFS that show it the important data structure algorithm. So, that's all about the article. Hope, it will be helpful and informative to you.
Next TopicDFS Algorithm
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








