| |
DS Tutorial
DS Array
DS Linked List
DS Stack
DS Queue
DS Tree
DS Graph
DS Searching
DS Sorting
Differences
Misc
DS MCQ

Detect and Remove Loop in a Linked ListIntroduction:The linked list is a fundamental data structure used in computer science and programming for many purposes. While they provide for greater dynamic memory allocation flexibility, they can also present difficulties if loops, commonly referred to as cyclic dependencies, are mistakenly included. A linked list's loops must be identified and eliminated in order to protect data integrity and avoid infinite loops that can cause program crashes or memory leaks. This article will investigate the techniques and algorithms for loop detection and elimination in linked lists. Fundamentals of Linked Lists:In a linked list, a linear data structure, an element known as a node is linked to other nodes. Data and a link to the node beyond it in the chain make up each node's two components. The final node often points to NULL to signify the end of the list. Linked lists can take on a wide range of forms, such as singly linked lists, doubly linked lists, and circular linked lists. A loop in a linked list arises when a node, or collection of nodes, links to a node that has already been toured once in the list. 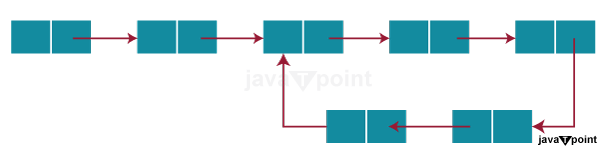
Detecting Loops:Before attempting to remove them, it is essential to identify loops in a linked list. Floyd's Tortoise and Hare Algorithm and hashing are the most popular algorithms for accomplishing this. 1. Floyd's Tortoise and Hare Algorithm:
2. Hashing:
Removing Loops:The next action is to eliminate the loop while maintaining the integrity of the linked list. There are numerous methods to accomplish this: 1. Using Floyd's Algorithm:
2. Hashing:
Python Implementation:The Python code for Floyd's Tortoise and Hare Algorithm with Hashing to find and eliminate loops in a single linked list is provided below. Output: Loop detected. Loop removed. 1 -> 2 -> 3 -> 4 -> 5 -> None Conclusion:To safeguard data integrity alongside avoiding programming issues, programmers must be familiar with detecting and removing loops in linked lists. Loops can be efficiently detected using algorithms like Floyd's Tortoise and Hare Algorithm and hashing, and they can be safely removed using a variety of techniques. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








