| |

Separate chaining for Collision HandlingDescribe collision.Two keys could possibly provide the same value since a hash function returns a little number for a key that is a large integer or string. A collision handling mechanism must be used to deal with the circumstance when a newly added key maps to a hash table slot that is already occupied. How often are collisions with the big table?Even if we have a large table to put the keys on, collisions are still highly frequent. Birthday Paradox is a crucial finding. With only 23 people, there is a 50% chance that two people will share the same birthday. Dealing with collisionsThere are primarily two ways to deal with collision:
Only independent chaining is mentioned in this article. The following post will cover Open addressing. Separate Chaining:With separate chaining, the array is implemented as a chain, which is a linked list. One of the most popular and often employed methods for handling accidents is separate chaining. This method is implemented using the linked list data structure. As a result, when numerous elements are hashed into the same slot index, those elements are added to a chain, which is a singly-linked list. Here, a linked list is created out of all the entries that hash into the same slot index. Now, using merely linear traversal, we can search the linked list with a key K. If the intrinsic key for any entry equals K, then we have identified our entry. The entry does not exist if we have searched all the way to the end of the linked list and still cannot find it. In separate chaining, we therefore get to the conclusion that if two different entries have the same hash value, we store them both in the same linked list one after the other. Let's use "key mod 7" as our simple hash function with the following key values: 50, 700, 76, 85, 92, 73, 101. 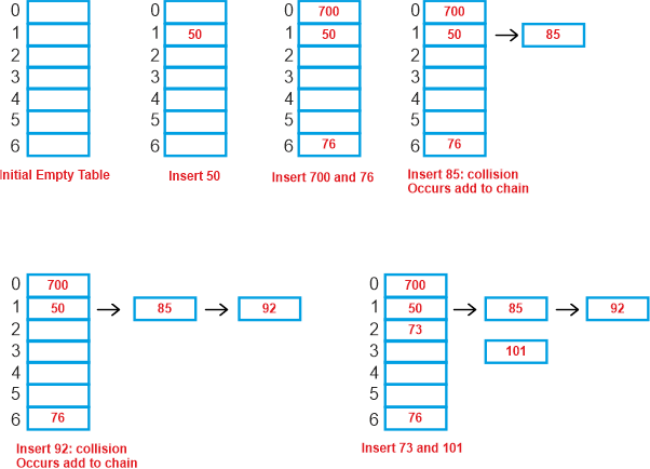
Advantages:
Disadvantages:
Performance of Chaining:Under the premise that each key has an equal likelihood of being hashed to any table slot, the performance of hashing may be assessed (simple uniform hashing). Data Structures For Storing Chains:
Summary
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








