| |

Blending vs StackingIntroductionStacking and Blending are two powerful and popular ensemble methods in machine learning. They are very similar, with the difference around how to allocate the training data. They are most noticeable for their popularity and performance in winning Kaggle competitions. StackingStacking or stacked generalisation was introduced by Wolpert. In essence, stacking predicts by using a meta-model trained from a pool of base models. The base models are trained using training data and asked to give their prediction; a different meta-model is then trained to use the outputs from base models to give the final prediction. 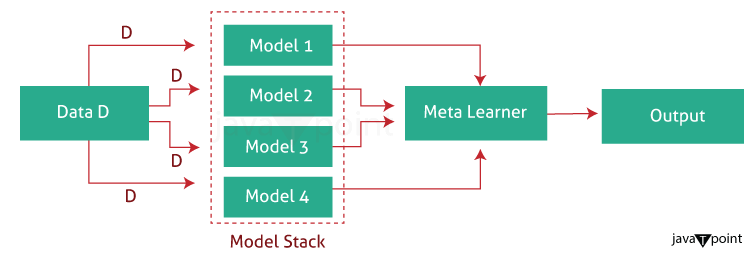
How Stacking Works
Example (Python):Output: Accuracy of the stacked model: 0.88 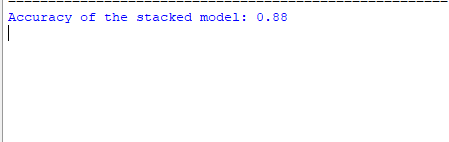
BlendingBlending is very similar to Stacking. It also uses base models to provide base predictions as new features, and a new meta-model is trained on the new features that give the final prediction. The only difference is that training of the meta-model is applied on a separate holdout set (e.g. 10% of train_data) rather than on a full and folded training set. 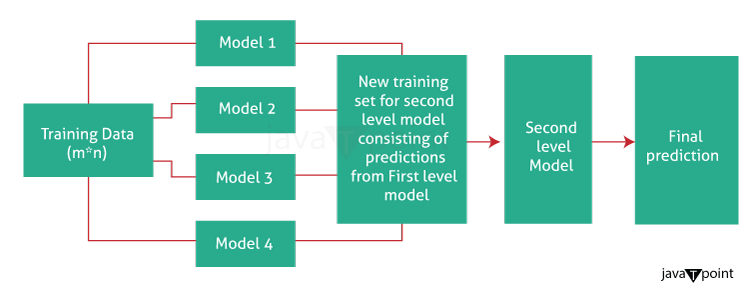
How Blending Works
Example (Python):Output: Accuracy of the blended model: 0.885 
Advantages and DisadvantagesStackingAdvantages
Disadvantages
BlendingAdvantages
Disadvantages
When to Use Stacking or BlendingThe preference among stacking and mixing relies on the specific problem and the computational assets. Stacking is typically favoured for better performance if computational assets and time are not subject. However, blending may be a higher desire when you have many base models or are worried about information leakage. Variations of StackingThere are numerous versions of stacking, including weighted stacking, in which the predictions of the base fashions are weighted primarily based on their performance. Another variation is stacking with characteristic choice, in which a subset of the bottom model predictions is used as a capability for the meta-version. Variations of BlendingBlending can also be varied by converting the holdout set's size or by using one-of-a-kind holdout sets for specific base models. This can help to reduce overfitting and enhance the overall performance of the blending model. ConclusionBoth Stacking and Blending are effective ensemble strategies that may enhance the performance of gadget learning models. They paint by combining the predictions of more than one base style to make the last prediction. The preference between stacking and blending relies on the specific necessities of your system, getting to know the hassle and the available assets.
Next TopicBloom Filters
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








