| |

Delete all occurrences of a given key in a linked listA related listing is a linear data structure where each element is a separate item. Each element (which we will call a node) of a list includes two items - the data and a reference to the next node. The closing node has a reference to null. The access factor into a related listing is called the head of the listing. It should be mentioned that the top isn't a separate kind of node, but the reference to the first node. If the list is empty, then the pinnacle is a null reference. In Python, we don't have related lists as a built-in fact's kind, however we will create a class to put in force the concept of related lists. In our implementation, a node in the linked list is represented for instance of the Node class, which has attributes: records and next. The data characteristic incorporates the facts we want to save, while next is a connection with the subsequent node inside the list. The deleteKey() characteristic in our implementation is used to delete all occurrences of a given key inside the related list. It works through iterating through the connected list and deleting the nodes which incorporate the given key. If the key is determined at the head of the list, it updates the top to the following node. For keys found in other positions, it updates the 'subsequent' reference of the preceding node to skip the node containing the important thing. This efficiently gets rid of all occurrences of the key from the related listing. Here's a simple Python code snippet that deletes all occurrences of a given key in a linked list. Output: 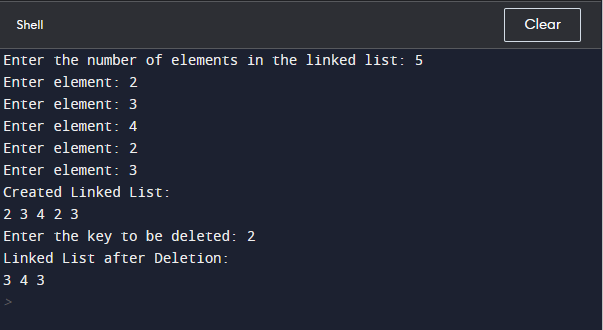
In this code, we first create a linked listing the use of the append feature. Then, we name the deleteKey() characteristic to get rid of all occurrences of a given key. Finally, we print the connected list after the deletion operation. The deleteKey() characteristic works via iterating via the linked list and deleting the nodes which comprise the given key. If the secret is discovered at the top of the list, it updates the head to the next node. For keys observed in different positions, it updates the 'subsequent' reference of the preceding node to pass the node containing the important thing. This efficiently eliminates all occurrences of the important thing from the linked listing. Please observe that this code assumes that the given key's present within the related list. If the key is not given inside the linked list, the feature will not make any changes. The time complexity of the feature to delete all occurrences of a given key in a related list is O(n), in which n is the variety of nodes inside the connected listing. This is because inside the worst-case situation, we may additionally want to traverse through all the nodes in the connected list. The auxiliary space complexity of the function is O(1). This is due to the fact we are not the usage of any more area that scales with the size of the enter. We are best the usage of a set quantity of area to save the brief variables, regardless of the dimensions of the connected listing. Therefore, the space complexity is regular.
Next TopicDesign a data structure that supports insert, delete, search and getRandom in constant time
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








