| |

Hashing - Open Addressing for Collision HandlingWe have talked about
Open Addressing for Collision HandlingSimilar to separate chaining, open addressing is a technique for dealing with collisions. In Open Addressing, the hash table alone houses all of the elements. The size of the table must therefore always be more than or equal to the total number of keys at all times (Note that we can increase table size by copying old data if needed). This strategy is often referred to as closed hashing. The foundation of this entire process is probing. We will comprehend several forms of probing later.
Although an item can be inserted into a deleted slot, the search continues after the slot has been empty. NOTE-
Open AddressingOpen addressing is when
The methods for open addressing are as follows:
The following techniques are used for open addressing: (a) Linear probingIn linear probing, the hash table is systematically examined beginning at the hash's initial point. If the site we receive is already occupied, we look for a different one. The rehashing function is as follows: table-size = (n+1)% rehash(key). As may be seen in the sample below, the usual space between two probes is 1. Let S be the size of the table and let hash(x) be the slot index calculated using a hash algorithm. Let's use "key mod 7" as a simple hash function with the following keys: 50, 700, 76, 85, 92, 73, 101. 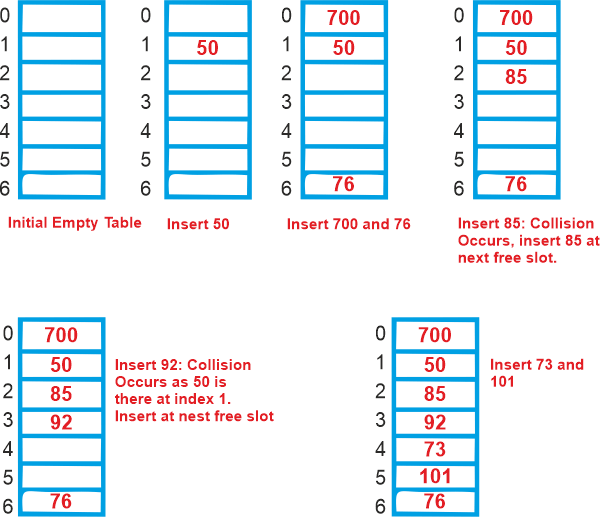
Linear probing problems:
Advantage-
Disadvantage-
Time Complexity: The worst time in linear probing to search an element is O ( table size ). This is due to
(b) Quadratic probingIf you pay close attention, you will notice that the hash value will cause the interval between probes to grow. The above-discussed clustering issue can be resolved with the aid of the quadratic probing technique. The mid-square method is another name for this approach. We search for the i2'th slot in the i'th iteration using this strategy. We always begin where the hash was generated. We check the other slots if only the location is taken. c) Double HashAnother hash function calculates the gaps that exist between the probes. Clustering is optimally reduced by the use of double hashing. This method uses a different hash function to generate the increments for the probing sequence. We search for the slot i*hash2(x) in the i'th rotation using another hash algorithm, hash2(x). Comparing the first three:
Because we traverse a Linked List by essentially jumping from one node to the next throughout the computer's memory, chaining's cache efficiency is poor. Because of this, the CPU is unable to cache nodes that haven't been visited yet, which is bad for us. However, since data isn't dispersed while using Open Addressing, the CPU can cache information for speedy access if it notices that a particular area of memory is frequently accessed. Performance of Open Addressing: Similar to Chaining, the performance of hashing can be assessed assuming that each key has an equal likelihood of being hashed to any slot of the table (simple uniform hashing) Load Factor (α)-Load factor (α) is defined as- 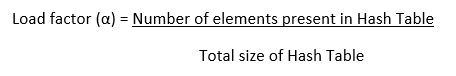
The load factor value in open addressing is always between 0 and 1. This is due to
Conclusions-
Next TopicIntroduction to Hashing
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








