| |

Find the largest subarray with 0 sum.Subarrays are contiguous parts of an array. Finding maximum length subarrays with specific properties like having a 0 sum has various applications in computer science and mathematics. For instance, finding maximum length 0-sum subarrays aids in financial analysis to detect fraud transactions that nullify each other. Similarly, it helps detect data inconsistencies in domains like bioinformatics and physics. In this article, we solve the problem of finding the length of the largest subarray having 0-sum in a given integer array. For example, in the collection [10, 2, -5, 1, 6], the longest 0-sum subarray is [2, -5, 1], having length 3. An efficient solution to this problem involves the usage of hashmap and tracking cumulative sum as we traverse the array from left to right. The key idea relies on the fact that if two prefix sums upto two indices i and j are the same, the sum of elements between indices i and j is 0. We use this property to efficiently find the length of the longest 0-sum subarray by storing prefix sums and their indices in a hashmap. Here is the outline for this article -
Approach 1: Brute Force MethodThe most straightforward approach to finding the longest subarray with 0 sum is to generate all possible subarrays of the given array and check their sums. This is essentially an exhaustive search exploring all combinations of start and end points marking subsequences in the array. More formally, we have two nested loops - the outer loop picks a starting element, and the inner loop considers all possible ending elements to construct subarrays beginning from the start element selected by the outer loop. We maintain a running sum in the inner loop, and if the sum becomes 0, we update the maximum length found so far. The time complexity of this brute force technique is O(n^2) since we have nested loops iterating upto n elements. Although simple to implement, this quadratic time complexity makes it infeasible for large input arrays. We will soon discuss a more efficient approach with better time complexity. But first, let's walk through the brute force method via some sample code for clarity, followed by an analysis of running time. Output: 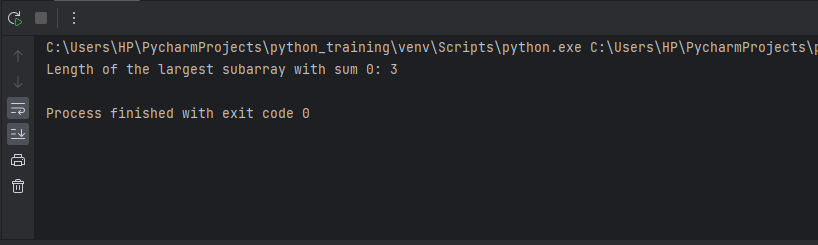
Explanation:
Approach 2: Prefix Sum TechniqueThe brute force method to find the longest 0-sum subarray runs in quadratic time complexity, which can be infeasible for significant inputs. We can optimize it using the prefix sum technique combined with hashing. The prefix sum concept relies on the fact that if the prefix sum up to two indices i and j are equal, the sum of elements between indices i and j is 0. We can leverage this by traversing the array once while tracking the current prefix sum. If we reencounter any prefix sum value, we can deduce that elements between the previously occurring index and the current instance will sum to 0. We store indices of unique prefix sums in a hash table. Comparing the current index with the previously held index gives us the length of the current 0-sum subarray. This technique reduces time to O(n) as the array is traversed only once. Next, we will walk through efficient Python code implementing this prefix sum hashing logic followed by run-time analysis. But first, understanding the crux - linking the same prefix sums to deduce 0-sum subarrays is vital before proceeding further. Output: 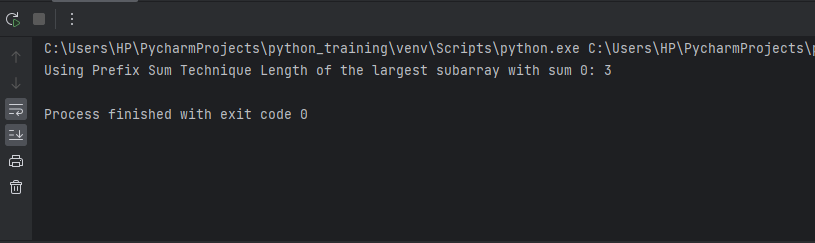
Explanation:
Approach 3: Using SetsIn the previous prefix sum technique, we used a hash table to store the prefix sums encountered while traversing the array. This allowed us to efficiently find a 0-sum subarray in linear time by linking exact prefix sums. However, searching in a hash table can be optimized using a Set instead, which gives constant time-containing checks. The key idea is to insert all prefix sums encountered into a Set. Checking the presence of any sum in the Set will convey whether it had occurred previously. Hence, exact sums indicate a 0-sum subarray from the index of the previous occurrence to the current instance. Sets provide average case O(1) search time, leading to linear time complexity. The advantage of using Set over the hash table is that it eliminates unnecessary indices storage. We only need to check the existence of the current prefix sum. If it exists in Set, we have found a 0-sum subarray; otherwise, we simply insert the current sum. This space optimization is beneficial for large arrays. Now, let's walk through the Python code, applying this logic and analyzing its run time complexity. Output: 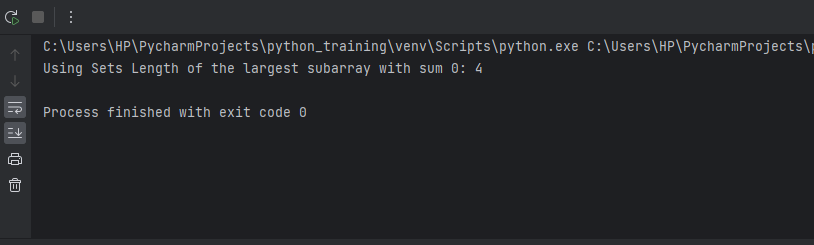
Explanation:
Next TopicFree Tree in Data Structures
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








