| |

Difference Between Prim's and Kruskal's algorithmIntroduction:In the field of graph theory, finding the minimum spanning tree (MST) of a given graph is a common problem with numerous applications. MSTs are used in various fields, such as network design, clustering, and optimization. Two popular algorithms to solve this problem are Prim's and Kruskal's algorithms. While both algorithms aim to find the minimum spanning tree of a graph, they differ in their approaches and the underlying principles they rely on. 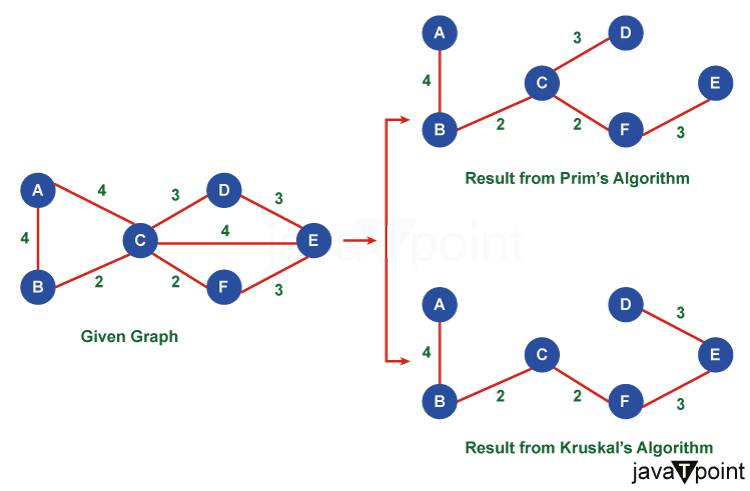
Prim's Algorithm:Prim's algorithm is a greedy algorithm that incrementally grows the minimum spanning tree from a starting vertex. The algorithm maintains two sets of vertices: one set contains the vertices already included in the MST, while the other set contains the remaining vertices. Prim's algorithm iteratively selects the vertex with the smallest edge weight that connects the two sets and adds it to the MST. The algorithm follows the following steps:
To accomplish this, examine all edges connected to the visited vertices and select the one with the lowest weight.
Key Characteristics of Prim's Algorithm:Prim's algorithm is a greedy approach, as it makes locally optimal choices at each step to construct the MST. It guarantees the generation of a connected and acyclic MST. The time complexity of Prim's algorithm is O(V^2) with a simple implementation using an adjacency matrix. However, using a priority queue can reduce the complexity to O(E log V). ProgramExplanation:
Program Output: 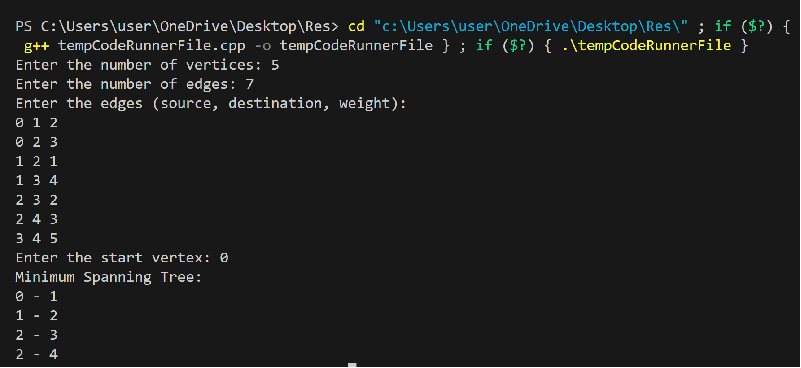
Kruskal's Algorithm:Kruskal's algorithm is another greedy algorithm used to find the minimum spanning tree. Unlike Prim's algorithm, Kruskal's algorithm processes the edges of the graph in ascending order of their weights. It incrementally adds edges to the MST as long as they do not create a cycle. The steps involved in Kruskal's algorithm are as follows:
To determine if adding an edge creates a cycle, Kruskal's algorithm utilizes the concept of disjoint sets. It keeps track of the subsets that contain each vertex and checks if adding an edge connects two vertices from the same subset. Key Characteristics of Kruskal's Algorithm:Kruskal's algorithm uses the concept of disjoint sets to detect cycles efficiently. It does not require a starting vertex and is not restricted to a connected graph. The time complexity of Kruskal's algorithm is O(E log E) or O(E log V) with efficient sorting algorithms, where E represents the number of edges and V the number of vertices. ProgramExplanation:
Program Output: 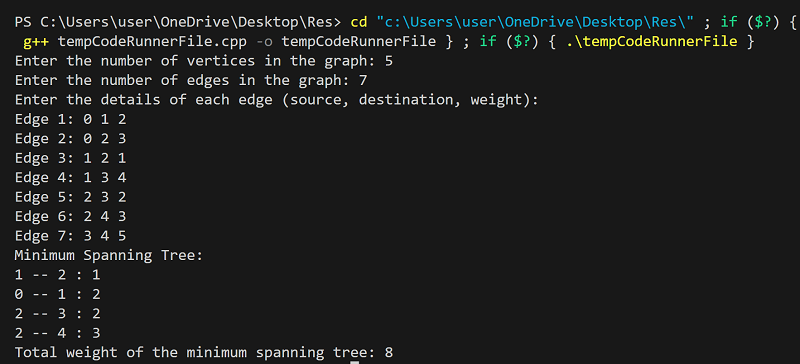
Differences in Approach:Approach: Prim's algorithm uses a vertex-based approach, focusing on growing the MST from a starting vertex. It gradually expands the tree by adding the minimum-weight edges connected to the visited vertices. Kruskal's algorithm uses an edge-based approach, sorting edges and adding them to the MST as long as they don't form a cycle. It constructs the MST by considering edges one by one in ascending order of their weights. Connectivity: Prim's algorithm ensures that the MST is always connected, even for disconnected input graphs. It starts with a single vertex and gradually expands the tree until it encompasses all vertices. Kruskal's algorithm can generate multiple trees in the case of a disconnected graph. It treats each vertex as an individual tree initially and merges them as edges are added, resulting in a forest of trees. Time Complexity: Prim's algorithm has a time complexity of O(V^2) with a simple implementation and O(E log V) with a priority queue. The choice of implementation depends on the density of the graph. Kruskal's algorithm has a time complexity of O(E log E) or O(E log V) with efficient sorting algorithms. It primarily depends on the number of edges rather than the number of vertices Advantages of Prim's Algorithm:Efficiency: Prim's algorithm performs well on dense graphs where the number of edges is close to the maximum possible. Its time complexity is O(V^2) with an adjacency matrix representation. Guaranteed MST: Prim's algorithm guarantees that the MST is found within V-1 iterations, where V is the number of vertices in the graph. Simplicity: Prim's algorithm is relatively easy to understand and implement, making it a popular choice for educational purposes. Disadvantages of Prim's Algorithm:Requirement of Connected Graphs: Prim's algorithm assumes a connected graph. If the graph has disconnected components, the algorithm needs to be applied to each component separately to find their respective minimum spanning trees. Inability to Handle Negative Weights: Prim's algorithm cannot handle graphs with negative edge weights since it may lead to incorrect MST results. Performance on Sparse Graphs: For sparse graphs with a significantly smaller number of edges, Prim's algorithm may be less efficient compared to Kruskal's algorithm. Applications of Prim's Algorithm:Network Design: Prim's algorithm is commonly used in network design scenarios to find the minimum cost network that connects various locations, minimizing the overall connection cost. Cluster Analysis: It can be applied to identify clusters or communities in a network, where each cluster is represented by a subtree of the minimum spanning tree. Advantages of Kruskal's Algorithm:Handling Disconnected Graphs: Kruskal's algorithm naturally handles disconnected graphs and produces a minimum spanning forest, which consists of multiple MSTs for each connected component. Handling Negative Weights (with No Negative Cycles): Kruskal's algorithm can handle graphs with negative edge weights, as long as there are no negative cycles present in the graph. Efficiency for Sparse Graphs: Kruskal's algorithm performs better on sparse graphs, where the number of edges is significantly smaller. Its time complexity is O(E log E), where E is the number of edges. Disadvantages of Kruskal's Algorithm:Sorting Overhead: Kruskal's algorithm requires sorting the edges based on their weights, which introduces an additional O(E log E) time complexity. Potential Forest Output: In the case of disconnected graphs, Kruskal's algorithm may produce a forest of multiple minimum spanning trees, which might not be desirable for some applications. Applications of Kruskal's Algorithm:Network Connectivity: Kruskal's algorithm is useful for determining whether a network is fully connected or not by finding the minimum spanning forest, which represents the connections between components. Image Segmentation: It can be applied in image processing tasks to partition an image into distinct regions by treating pixels as vertices and the similarity between pixels as edge weights.
Next TopicInterpolation Search
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








