| |

B Tree PropertiesTraditional binary search trees have certain unpleasant limitations. Introducing the B-Tree, a versatile data structure that handles enormous quantities of data with ease. Traditional binary search trees can become unfeasible when it comes to storing and searching vast amounts of data because of their poor speed and high memory utilization. B-Trees, often referred to as Balanced Trees or B-Trees, are a kind of self-balancing tree that was created expressly to get around these restrictions. B-Trees, also known as 'Big Key' trees, are distinguished from conventional binary search trees by the enormous number of keys that they can hold in a single node. A B-Tree can have many keys at each node, which increases the branching factor and lowers the height of the tree. Because of the reduced disc I/O caused by this lower height, search and insertion operations are completed more quickly. Hard drives, flash memory, and CD-ROMs are examples of storage devices that benefit most from B-Trees because of their sluggish, clumsy data access. 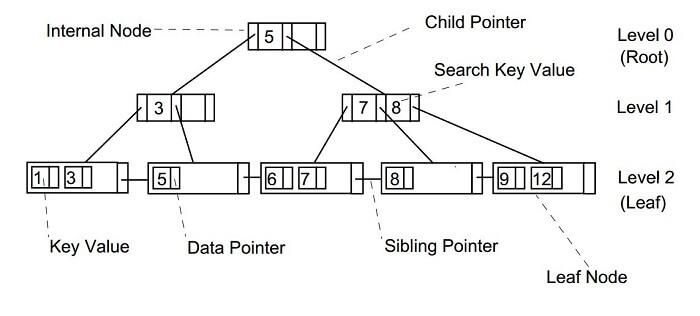
Each node in a B-Tree must have a minimum number of keys in order for the tree to remain balanced. No matter how the tree is initially shaped, this balance ensures that time complexity for operations like insertion, deletion, and searching is always O(log n). B-Tree Time Complexity:
Here, the total number of elements in the B-tree is 'n'. B-tree Properties:
NOTE: The B-smallest Tree's possible height when there are n nodes and m children (the most children a node can have) is: 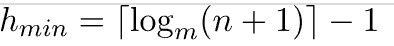
With n nodes and t being the smallest n umber of children, a non-root node can have, the greatest height of the B-Tree that can exist is: 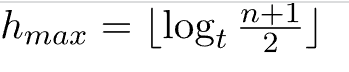
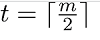
Origin of B Tree
Why is a B-tree data structure necessary?The demand for faster access to physical storage medium such a hard disc led to the development of B-tree. The secondary storage devices have a bigger capacity but are slower. These kinds of data structures, which reduce disc accesses, were required. One key can only be stored in a node of another data structure, such as a binary search tree, AVL tree, red-black tree, etc. The height of such trees becomes very vast, and the access time increases if you need to store a lot of keys. B-tree, on the other hand, can contain numerous child nodes and can store numerous keys in a single node. This causes the height to dramatically fall, enabling faster accesses of the disks. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








