| |

Inorder Predecessor and Successor in a Binary Search TreeBinary search trees (BSTs) are a famous data structure that stores data in a way that allows quick lookups, insertions, and deletions. An important concept when working with BSTs is finding the in-order predecessor and successor of a node. The inorder predecessor of a node is the node that would come immediately before it in an inorder traversal of the BST. Similarly, the inorder successor is the node that would go directly after. Being able to find these nodes quickly is helpful for many BST operations. In this article, we'll look at how to find in-order predecessors and successors in a binary search tree. 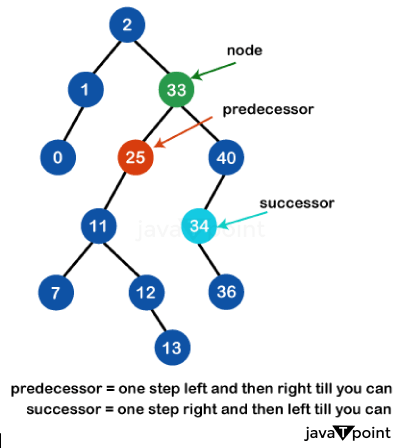
Inorder Traversal RefresherBefore jumping into predecessors and successors, let's do a quick review of inorder traversal. Inorder traversal of a BST visits the nodes in ascending order. It works by recursively traversing the left subtree, calling the current node, and then recursively traversing the right subtree. For example, here is how inorder traversal would work on the following sample BST: The nodes would be visited in the order of 2, 5, 8, 15, 17, 20, and 25. So when we talk about a node's inorder predecessor or successor, we mean the node that comes immediately before or after it in this inorder sequence. Finding Inorder PredecessorLet's start with finding a node's inorder predecessor. The inorder predecessor is the node that would come immediately before the node during an inorder traversal. There are a few critical cases to consider here: Node has left subtree If the node has a non-empty left subtree, then the predecessor is the rightmost node in that subtree. We can find it by starting at the node's left child and repeatedly following right child pointers until we can't anymore. For example, the predecessor of 15 in the example tree would be 8. We start at 15's left child 5, then go right once to 8. The node is the left child of the parent. If the node is the left child of its parent, then the parent is the predecessor. So, for node 5, its predecessor would be 2 (its parent). Node is the right child of a parent. If the node is the right child of its parent, then we need to recursively go up the tree following left child pointers until we find a node that is the left child of its parent. That parent is the predecessor. The predecessor of 17 is 15 because 17 is the right child. So we go up to 20 and follow its left child pointer to 15. Node has no left subtree and is not a left child. In this case, we recursively keep going up the tree following parent pointers until we find a node that meets one of the previous cases. The predecessor of 25 is 20 since 25 has no left subtree and is not a left child. We traverse until we find 20, which is the left child of its parent. So, in summary, to find the inorder predecessor:
Finding Inorder SuccessorThe inorder successor can be found using similar logic but reversing left and right. The successor is the node that comes immediately after the node during an inorder traversal. The critical cases are: Node has the right subtree If the node has a non-empty right subtree, then the successor is the leftmost node in that subtree. For 8, its successor would be 15, since 15 is the leftmost node in 8's right subtree. Node is the right child of a parent. If the node is the right child of its parent, then the parent is the successor. So the successor of 20 is 25. The node is the left child of the parent. If the node is the left child of its parent, then we traverse up recursively, looking for a node that is the right child of its parent. That parent is the successor. 17's successor is 20 since 17 is a left child. We go up to 15 and follow its right child pointer to 20. Node has no right subtree and is not a right child In this case, we keep traversing until we find a node that satisfies one of the other cases. 5's successor is 8 since it has no right subtree and is not a right child. We traverse up to 15 and then follow its right child to 8. In summary, to find the inorder successor:
Python ImplementationApproach 1: Recursive ApproachHere is an introduction to the recursive approach for finding order predecessor and successor in a binary search tree: In a binary search tree (BST), the nodes are arranged such that the left subtree of a node contains values less than the node, and the right subtree contains values greater than the node. This property allows us to search efficiently. Another helpful property of BSTs is that an in-order traversal of the tree visits the nodes in sorted order. The node called before a given node is its inorder predecessor, and the node seen just after is the inorder successor. We can leverage these properties to find the inorder predecessor and successor of a given key recursively. The key idea is to traverse the BST recursively, keeping track of potential predecessor and successor nodes. When traversing left, a node becomes a potential predecessor. When going right, it becomes a possible successor. Once we reach the node with the matching key, we must look at its left and right subtrees. The maximum value in the left subtree is the predecessor and the minimum value in the right subtree is the successor. This recursive approach elegantly utilizes the BST structure to find predecessor and successor without needing auxiliary storage. We don't need to maintain a visited set. The recursion naturally ensures we don't repeat work. This makes the solution simple and efficient. The recursive calls act as an implicit stack to track the potential candidates. Returning up the call stack gives us the answer. This demonstrates the power of recursion for tree problems. Overall, the recursive approach is intuitive and optimal, leveraging the innate BST structure. Program Output: Inorder Predecessor: 20 Inorder Successor: 40 Explanation:
Approach 2: Iterative ApproachThe recursive approach is an elegant solution that utilizes the innate structure of a binary search tree to find the predecessor and successor for a given key. However, recursion has its drawbacks - it consumes stack space proportional to the height of the tree and involves function call overheads. For very skewed or deep trees, we could run into stack overflow errors. An alternative is to adopt an iterative approach. The key idea here is to traverse the binary tree iteratively using a pointer instead of recursive calls. We avoid recursion altogether. The traversal logic is encapsulated in a while loop, which iterates through the tree nodes systematically. To track the potential predecessor and successor, we maintain two reference variables, which get updated when we take left or right turns during traversal. The core is that the pointer tracks our current position, while the reference variables track the parent nodes from where we arrived at the current node. Once the node with a matching key is found, the reference variables will point to the predecessor and successor, respectively, based on the relative value comparisons done during traversal. We only need to check the node's left and right subtrees to confirm the final values. This iterative style traversal consumes only O(1) auxiliary space since no recursion stack is involved. It is more space-efficient and can handle skewed trees gracefully. The iterative logic may also be more straightforward to understand compared to recursion. Overall, it complements the elegance of the recursive approach by providing an efficient and robust solution. Algorithm:
Advantages:
Output: Inorder Predecessor: 30 Inorder Successor: 40 Here are the key points about this iterative approach:
Next TopicWhat is Internal Sorting
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








