Reduce the string by removing K consecutive identical characters
Introduction:
Many algorithms and approaches are used in the field of computer science and string manipulation to address distinct problems. Reducing strings by eliminating K consecutively similar characters is one such task. The fact that this problem incorporates aspects of optimization and data manipulation makes it very intriguing. We will examine the problem statement, look into potential fixes, and talk about the ramifications and uses of the solution in this article.
Problem Statement:
The objective of the problem of decreasing a string by eliminating K consecutive identical characters is to remove all K consecutive identical characters from the string until there are no more such substrings of length K. Until no more reduction is feasible, the procedure is repeated iteratively. The goal is to follow this guideline as closely as possible without extending the string's length.
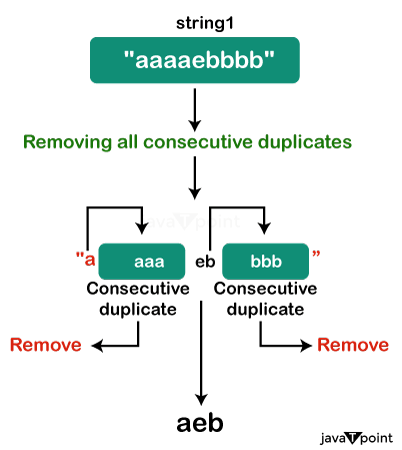
Solution Approaches:
- Brute Force: Using an iterative scan of the string and the removal of K consecutive identical characters as they are found, the brute force method is one way to solve this problem. Until no more of these substrings can be located, this process is repeated. Though conceptually simple, this approach is rather inefficient for large strings because it may need a lot of iterations.
- Stack-Based Methodology: Utilizing a stack data structure to save the string's non-reducible portion is an optimal option. Characters that are identical in succession are pushed onto the stack when they are found. Characters that are consecutively identical more than K are not added to the stack; instead, they are removed. The elements in the stack reflect the shortened string after the entire string has been processed.
- Recursive Solution: Using a recursive function is an additional strategy for solving this issue. The method can be made to look for and eliminate K consecutively identical characters from the input string. After that, it can be called again on the changed string until no more reductions are feasible. Although this method might not be the most effective, it offers a succinct and straightforward solution.
- Dynamic Programming: Another effective method for resolving this issue is dynamic programming. The parts of the string that need to be eliminated can be found by keeping an array that counts the consecutive identical characters at each point in the string. With this method, every character is handled just once, making the solution more effective.
Implications and Applications:
There are various practical applications and consequences for the challenge of shortening strings by eliminating K consecutive identical characters:
- Data compression: Reducing successive identical characters in data compression algorithms can assist in reducing the compressed data's size. Data can be further compressed without a major loss of information by using the approaches that have been outlined.
- Text Processing: This issue is relevant to text processing for functions like autocorrection and spell-checking. It can assist in locating and fixing typographical errors by decreasing the number of consecutive identical characters.
- DNA Sequence Analysis: This problem can be used to examine DNA sequences in the field of bioinformatics. DNA analysis can be made simpler by removing nucleotides that are consecutively identical.
- Image Compression: To maximize storage capacity and transmission speed, an image's successive identical pixels might be decreased.
Program:
Output:
Original String: aabbccccddeeeeeff
Reduced String: abcdef
Real-World Applications:
- Text compression: This problem is used to decrease the representation of the input data and reduce successive identical characters in data compression algorithms such as Run-Length Encoding (RLE). File storage, image, and video compression, and data transfer all make extensive use of this.
- Spelling and Grammar Correction: Identifying and decreasing consecutive identical characters can aid in the identification and correction of frequent typographical errors when analyzing text, particularly in spell-checking and grammar correction software. For example, the word "loooove" could be changed to "love."
- Genetic Sequencing: To identify trends, mutations, and gene sequences, DNA and RNA sequences are frequently examined in bioinformatics. Reducing successive identical nucleotides makes these sequences easier to represent and facilitates a variety of genetic investigations.
- Speech Recognition: Repeated or redundant words or phrases may appear in transcribed speech produced by speech recognition systems. The output can be made more succinct and coherent by cutting away such consecutively repeated items.
- Data deduplication: It is the act of identifying and removing consecutively identical data blocks from backup and data storage systems to conserve storage space. When the same data is repeated repeatedly, this can drastically lower the amount of storage needed.
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








