| |

Hashing in Data StructureIntroduction to Hashing in Data Structure:Hashing is a popular technique in computer science that involves mapping large data sets to fixed-length values. It is a process of converting a data set of variable size into a data set of a fixed size. The ability to perform efficient lookup operations makes hashing an essential concept in data structures. What is Hashing?A hashing algorithm is used to convert an input (such as a string or integer) into a fixed-size output (referred to as a hash code or hash value). The data is then stored and retrieved using this hash value as an index in an array or hash table. The hash function must be deterministic, which guarantees that it will always yield the same result for a given input. Hashing is commonly used to create a unique identifier for a piece of data, which can be used to quickly look up that data in a large dataset. For example, a web browser may use hashing to store website passwords securely. When a user enters their password, the browser converts it into a hash value and compares it to the stored hash value to authenticate the user. What is a hash Key?In the context of hashing, a hash key (also known as a hash value or hash code) is a fixed-size numerical or alphanumeric representation generated by a hashing algorithm. It is derived from the input data, such as a text string or a file, through a process known as hashing. Hashing involves applying a specific mathematical function to the input data, which produces a unique hash key that is typically of fixed length, regardless of the size of the input. The resulting hash key is essentially a digital fingerprint of the original data. The hash key serves several purposes. It is commonly used for data integrity checks, as even a small change in the input data will produce a significantly different hash key. Hash keys are also used for efficient data retrieval and storage in hash tables or data structures, as they allow quick look-up and comparison operations. How Hashing Works?The process of hashing can be broken down into three steps:
Hashing Algorithms:There are numerous hashing algorithms, each with distinct advantages and disadvantages. The most popular algorithms include the following:
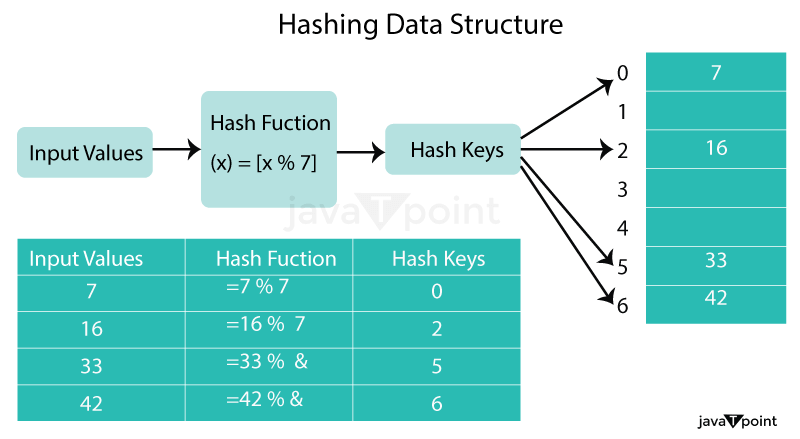
Hash Function:Hash Function: A hash function is a type of mathematical operation that takes an input (or key) and outputs a fixed-size result known as a hash code or hash value. The hash function must always yield the same hash code for the same input in order to be deterministic. Additionally, the hash function should produce a unique hash code for each input, which is known as the hash property. There are different types of hash functions, including:
This method involves dividing the key by the table size and taking the remainder as the hash value. For example, if the table size is 10 and the key is 23, the hash value would be 3 (23 % 10 = 3).
This method involves multiplying the key by a constant and taking the fractional part of the product as the hash value. For example, if the key is 23 and the constant is 0.618, the hash value would be 2 (floor(10*(0.61823 - floor(0.61823))) = floor(2.236) = 2).
This method involves using a random hash function from a family of hash functions. This ensures that the hash function is not biased towards any particular input and is resistant to attacks. Collision ResolutionOne of the main challenges in hashing is handling collisions, which occur when two or more input values produce the same hash value. There are various techniques used to resolve collisions, including:
Example of Collision ResolutionLet's continue with our example of a hash table with a size of 5. We want to store the key-value pairs "John: 123456" and "Mary: 987654" in the hash table. Both keys produce the same hash code of 4, so a collision occurs. We can use chaining to resolve the collision. We create a linked list at index 4 and add the key-value pairs to the list. The hash table now looks like this: 0: 1: 2: 3: 4: John: 123456 -> Mary: 987654 5: Hash Table:A hash table is a data structure that stores data in an array.Typically, a size for the array is selected that is greater than the number of elements that can fit in the hash table. A key is mapped to an index in the array using the hash function. The hash function is used to locate the index where an element needs to be inserted in the hash table in order to add a new element. The element gets added to that index if there isn't a collision.If there is a collision, the collision resolution method is used to find the next available slot in the array. The hash function is used to locate the index that the element is stored in order to retrieve it from the hash table. If the element is not found at that index, the collision resolution method is used to search for the element in the linked list (if chaining is used) or in the next available slot (if open addressing is used). Hash Table OperationsThere are several operations that can be performed on a hash table, including:
Creating a Hash Table:Hashing is frequently used to build hash tables, which are data structures that enable quick data insertion, deletion, and retrieval. One or more key-value pairs can be stored in each of the arrays of buckets that make up a hash table. To create a hash table, we first need to define a hash function that maps each key to a unique index in the array. A simple hash function might be to take the sum of the ASCII values of the characters in the key and use the remainder when divided by the size of the array. However, this hash function is inefficient and can lead to collisions (two keys that map to the same index). To avoid collisions, we can use more advanced hash functions that produce a more even distribution of hash values across the array. One popular algorithm is the djb2 hash function, which uses bitwise operations to generate a hash value: This hash function takes a string as input and returns an unsigned long integer hash value. The function initializes a hash value of 5381 and then iterates over each character in the string, using bitwise operations to generate a new hash value. The final hash value is returned. Hash Tables in C++In C++, the standard library provides a hash table container class called unordered_map. The unordered_map container is implemented using a hash table and provides fast access to key-value pairs. The unordered_map container uses a hash function to calculate the hash code of the keys and then uses open addressing to resolve collisions. To use the unordered_map container in C++, you need to include the <unordered_map> header file. Here's an example of how to create an unordered_map container in C++: Explanation:
Program Output: 
Inserting Data into a Hash TableTo insert a key-value pair into a hash table, we first need toas an index into the array to store the key-value pair. If another key maps to the same index, we have a collision and need to handle it appropriately. One common method is to use chaining, where each bucket in the array contains a linked list of key-value pairs that have the same hash value. Here is an example of how to insert a key-value pair into a hash table using chaining: Explanation:
However, if there is already a node present at that index in the hash_table array, the function needs to handle the collision. It traverses the linked list starting from the current node (hash_table[hash_value]) and moves to the next node until it reaches the end (curr_node->next != NULL). Once the end of the list is reached, the new node is appended as the next node (curr_node->next = new_node). Implementation of Hashing in C++:Let's see an implementation of hashing in C++ using open addressing and linear probing for collision resolution. We will implement a hash table that stores integers. Explanation:
Program Output: 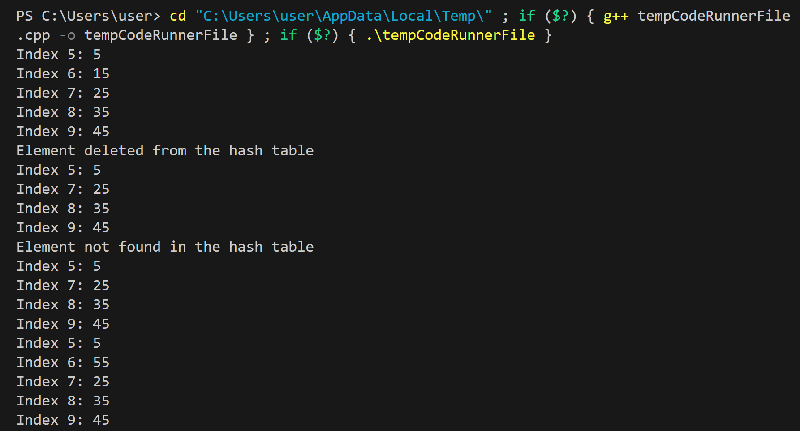
Applications of HashingHashing has many applications in computer science, including:
Advantages of Hashing:
Limitations of Hashing:
Conclusion:In conclusion, hashing is a widely used technique in a data structure that provides efficient access to data. It involves mapping a large amount of data to a smaller hash table using a hash function, which reduces the amount of time needed to search for specific data elements. The hash function ensures that data is stored in a unique location within the hash table and allows for easy retrieval of data when needed. Hashing has several advantages over other data structure techniques, such as faster retrieval times, efficient use of memory, and reduced collisions due to the use of a good hash function. However, it also has some limitations, including the possibility of hash collisions and the need for a good hash function that can distribute data evenly across the hash table. Overall, hashing is a powerful technique that is used in many applications, including database indexing, spell-checking, and password storage. By using a good hash function and implementing appropriate collision resolution techniques, developers can optimize the performance of their applications and provide users with a seamless experience.
Next TopicPrimitive Data Structure
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








