| |

Tree Data StructureWe read the linear data structures like an array, linked list, stack and queue in which all the elements are arranged in a sequential manner. The different data structures are used for different kinds of data. Some factors are considered for choosing the data structure:
A tree is also one of the data structures that represent hierarchical data. Suppose we want to show the employees and their positions in the hierarchical form then it can be represented as shown below: 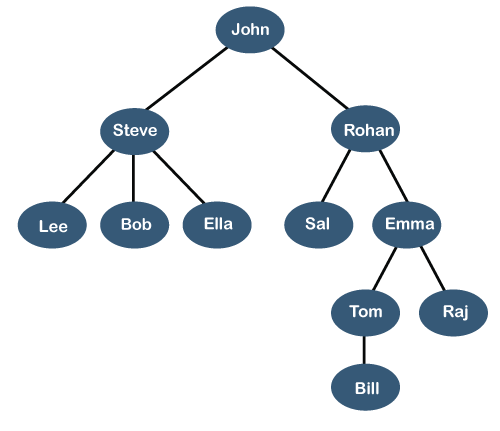
The above tree shows the organization hierarchy of some company. In the above structure, john is the CEO of the company, and John has two direct reports named as Steve and Rohan. Steve has three direct reports named Lee, Bob, Ella where Steve is a manager. Bob has two direct reports named Sal and Emma. Emma has two direct reports named Tom and Raj. Tom has one direct report named Bill. This particular logical structure is known as a Tree. Its structure is similar to the real tree, so it is named a Tree. In this structure, the root is at the top, and its branches are moving in a downward direction. Therefore, we can say that the Tree data structure is an efficient way of storing the data in a hierarchical way. Let's understand some key points of the Tree data structure.
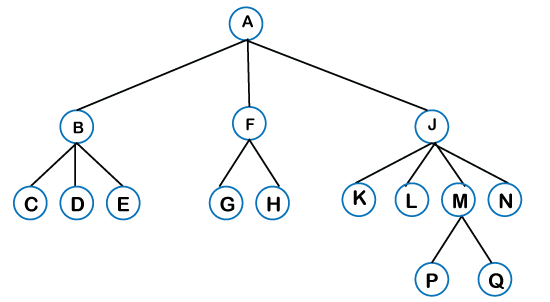
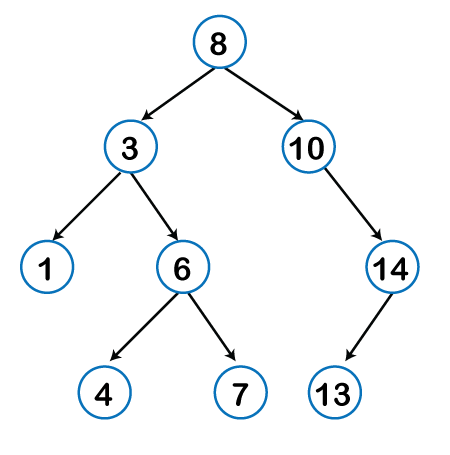
Some basic terms used in Tree data structure. Let's consider the tree structure, which is shown below: 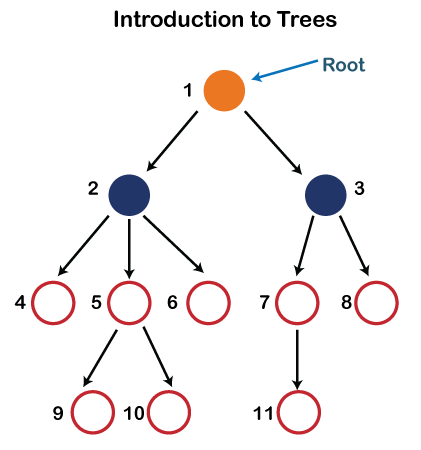
In the above structure, each node is labeled with some number. Each arrow shown in the above figure is known as a link between the two nodes.
Properties of Tree data structure
Based on the properties of the Tree data structure, trees are classified into various categories. Implementation of TreeThe tree data structure can be created by creating the nodes dynamically with the help of the pointers. The tree in the memory can be represented as shown below: 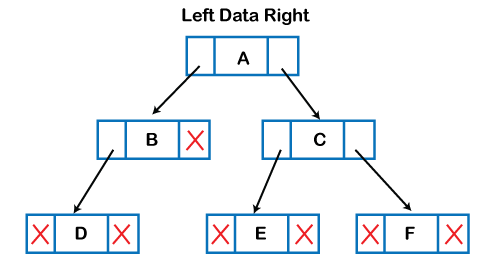
The above figure shows the representation of the tree data structure in the memory. In the above structure, the node contains three fields. The second field stores the data; the first field stores the address of the left child, and the third field stores the address of the right child. In programming, the structure of a node can be defined as: The above structure can only be defined for the binary trees because the binary tree can have utmost two children, and generic trees can have more than two children. The structure of the node for generic trees would be different as compared to the binary tree. Applications of treesThe following are the applications of trees:
Types of Tree data structureThe following are the types of a tree data structure:
A node can be created with the help of a user-defined data type known as struct, as shown below: The above is the node structure with three fields: data field, the second field is the left pointer of the node type, and the third field is the right pointer of the node type. To know more about the binary search tree, click on the link given below: https://www.javatpoint.com/binary-search-tree It is one of the types of the binary tree, or we can say that it is a variant of the binary search tree. AVL tree satisfies the property of the binary tree as well as of the binary search tree. It is a self-balancing binary search tree that was invented by Adelson Velsky Lindas. Here, self-balancing means that balancing the heights of left subtree and right subtree. This balancing is measured in terms of the balancing factor. We can consider a tree as an AVL tree if the tree obeys the binary search tree as well as a balancing factor. The balancing factor can be defined as the difference between the height of the left subtree and the height of the right subtree. The balancing factor's value must be either 0, -1, or 1; therefore, each node in the AVL tree should have the value of the balancing factor either as 0, -1, or 1. To know more about the AVL tree, click on the link given below: https://www.javatpoint.com/avl-tree The red-Black tree is the binary search tree. The prerequisite of the Red-Black tree is that we should know about the binary search tree. In a binary search tree, the value of the left-subtree should be less than the value of that node, and the value of the right-subtree should be greater than the value of that node. As we know that the time complexity of binary search in the average case is log2n, the best case is O(1), and the worst case is O(n). When any operation is performed on the tree, we want our tree to be balanced so that all the operations like searching, insertion, deletion, etc., take less time, and all these operations will have the time complexity of log2n. The red-black tree is a self-balancing binary search tree. AVL tree is also a height balancing binary search tree then why do we require a Red-Black tree. In the AVL tree, we do not know how many rotations would be required to balance the tree, but in the Red-black tree, a maximum of 2 rotations are required to balance the tree. It contains one extra bit that represents either the red or black color of a node to ensure the balancing of the tree.
The splay tree data structure is also binary search tree in which recently accessed element is placed at the root position of tree by performing some rotation operations. Here, splaying means the recently accessed node. It is a self-balancing binary search tree having no explicit balance condition like AVL tree. It might be a possibility that height of the splay tree is not balanced, i.e., height of both left and right subtrees may differ, but the operations in splay tree takes order of logN time where n is the number of nodes. Splay tree is a balanced tree but it cannot be considered as a height balanced tree because after each operation, rotation is performed which leads to a balanced tree.
Treap data structure came from the Tree and Heap data structure. So, it comprises the properties of both Tree and Heap data structures. In Binary search tree, each node on the left subtree must be equal or less than the value of the root node and each node on the right subtree must be equal or greater than the value of the root node. In heap data structure, both right and left subtrees contain larger keys than the root; therefore, we can say that the root node contains the lowest value. In treap data structure, each node has both key and priority where key is derived from the Binary search tree and priority is derived from the heap data structure. The Treap data structure follows two properties which are given below:
B-tree is a balanced m-way tree where m defines the order of the tree. Till now, we read that the node contains only one key but b-tree can have more than one key, and more than 2 children. It always maintains the sorted data. In binary tree, it is possible that leaf nodes can be at different levels, but in b-tree, all the leaf nodes must be at the same level. If order is m then node has the following properties:
The root node must contain minimum 1 key and all other nodes must contain atleast ceiling of m/2 minus 1 keys.
Next TopicBinary Tree
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








