| |

Bloom FiltersA Bloom filter is a space-efficient probabilistic data structure that is used to test whether an element is a member of a set. It was conceived by Burton Howard Bloom in 1970. The primary advantage of a Bloom filter over other data structures is its impressive space and time efficiency. Understanding Bloom FiltersUnder the hood, a Bloom filter is an array of bits, all set to zero initially. The size of this bit array depends on the number of elements expected to be stored and the desired false positive rate. A Bloom filter uses multiple hash functions to map each element to one or more array indexes. When an element is added to the filter, the bits at the hashed indexes are set to 1. When querying for an element, the filter checks the bits at the hashed indexes. If any of the bits are 0, the element is not in the set. If all bits are 1, the element might be in the set. 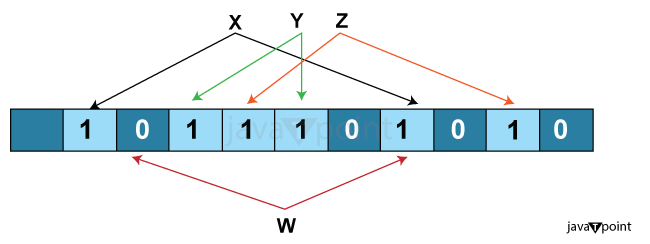
Key Properties of Bloom Filters
Bloom Filter OperationsA Bloom filter supports two primary operations:
Bloom filter WorkingTake a binary array of 'm' bits initialized with 0 for up to n different elements, set 'k' bits to at least one within the position chosen via the output of all the n exceptional factors after passing through hash functions. Now take the detail you want to perceive if it's far already present or no longer. Pass it through the equal hash characteristic, if all bits are set, the detail probable already exists, with a fake tremendous charge of p; if any of the bits are not set, the detail does no longer exist. Example of a Bloom FilterConsider a Bloom filter with a bit array of size 10 and three hash functions. Let's add the string "hello" to the filter. Suppose the hash functions map "hello" to the indexes 1, 3, and 7. The bit array after the insert operation would look like this: 0 1 0 1 0 0 0 1 0 0 Now, if we perform a lookup for "hello", the filter checks the bits at indexes 1, 3, and 7. Since all these bits are 1, the filter reports that "hello" might be in the set. Understanding using code:Output: 
Applications of Bloom FiltersBloom filters are used in various applications where space efficiency is crucial. They are used in databases, caches, routers, and other systems to quickly decide whether a given item is in a set. For example, a web browser might use a Bloom filter to check whether a URL is in a set of malicious URLs. Limitations of Bloom FiltersWhile Bloom filters are highly space and time-efficient, they do come with some limitations:
Despite these limitations, Bloom filters are a powerful tool when used in the right context. Their space and time efficiency make them an excellent choice for large-scale systems that need to test set membership quickly and efficiently. Optimizing Bloom FiltersWhile Bloom filters are already space-efficient, there are ways to optimize them further:
Next TopicCount Array Pairs Divisible by k
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








