| |

COMPUTER SCIENCE QUIZ - I: Part 3Topic 3 - DATABASE MANAGEMENT SYSTEM Q.1 Assume that R in an entity-relationship (ER) model is a many-to-one link between entity sets E1 and E2. Assume that E1 and E2 are totally involved in R and that E1's cardinality is higher than the cardinality of E2. Which of the following statements regarding R is true?
Ans. (a) Every object in E1 has precisely one linked entity in E2. Explanation: Given, E1 and E2 are participating Totally and |E1| > |E2|. The relation R is many-to-one. The relationship can be observed from the given diagram. 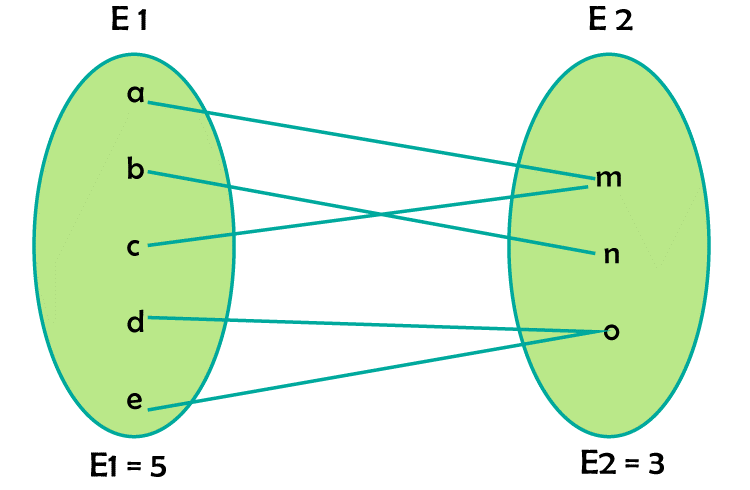
We can conclude that every object in E1 is linked to exactly one object in E2. Hence, (a) is the correct answer. Q. 2 A and B entity types make up an ER model of a database. These are linked together by a relationship R that lacks an independent attribute. In which of the following scenarios is it possible to combine R's relational table with A's?
Ans. (c) R is a many-to-one relationship, and A has complete involvement in R. Explanation: When the relation is one-to-many or many-to-one, we can merge the relationship table with the entity which is on the many side of the relationship by putting the primary key of the entity on one side as foreign key and priority is given to the entity which participates totally. Hence, we can conclude that option (c) is the correct answer. Q. 3 Which of the following is INACCURATE in terms of the basic ER and relational models?
Ans. (c) An attribute may have more than one value in a row of a relational table Explanation: In and relationship table, A cell cannot contain more than one value in it. For multivalued attributes, we create one more table. Q. 4 Let's assume that E1 and E2 are two entities in an E/R diagram with basic single-valued properties. The relationships R1 and R2 between E1 and E2 are one-to-many and many-to-many, respectively. There are no unique properties shared by R1 and R2. How many minimum numbers of tables are needed in the relational model to represent this scenario?
Ans. (b) 3 Explanation: The minimum number of tables required is as follows: One table to represent E1, One table to represent E2, As R1 is a one-to-many relationship, we can represent it by placing the primary key of E1 into E2 as the foreign key. And R2 is many-to-many relationship, we need one more table to represent this relationship. Hence, minimum number of tables required is 3. Q. 5 Which of the following claims regarding weak entity sets is FALSE?
Ans. (d) The relationships between tuples in a weak entity set and tuples in a strong entity set are not taken into account when partitioning tuples. Explanation: Weak entity sets those that do not process enough characteristics to create a primary key. Although it contains discriminator attributes (partial keys) that provide some information about the entity set, this information is insufficient to identify each tuple uniquely. The lack of a weak entity set will result in duplication and potential contradictions because it reflects the logical structure of an entity's dependence on another and can be eliminated automatically when its strong entity is deleted. Q. 6 Select the correct option.
Ans. (d) Primary Key ⊆ Candidate Key ⊆ Super Key Explanation: All primary, candidate and Super keys are capable of uniquely identifying a tuple. The minimal super keys are called candidate keys, and one of the candidate keys is selected as the primary key. Hence, the correct order is Primary Key ⊆ Candidate Key ⊆ Super Key. Q. 7 The purpose of relational database schema normalization is NOT for
Ans. (a) The purpose of relational database schema normalization is NOT for lowering the number of joins needed to fulfil a query. Explanation: Normalization - In order to accomplish the desired features of eliminating duplication using Decomposition, the normalization of data (Decomposition of Relation) can be viewed as a process of assessing the relation schema that has been provided. Normalization removes redundant data, assures the enforcement of function dependencies and eliminates abnormalities. The idea of joining is altogether a different story. Q. 8 If a relationship exists in both 2NF and 3NF forms, then:
Ans. (a) If a relationship exists in both 2NF and 3NF forms, then No non-prime attribute depends on any other non-prime attributes. Explanation: Partial dependencies are removed in 2NF, and transitive dependencies are removed in 3NF. Partial dependency occurs when a non-prime attribute depends on a subset of any candidate key and transitive dependency occurs when a non-prime attribute depends on another non-prime attribute. Hence, (a) is the correct answer. Q. 9 Take into account the relationship schema below. Every non-trivial functional dependency for the schema is listed below. The underlined attribute is the primary key. Enrollment (rollno, courseid, email) Non-trivial functional dependencies: rollno, courseid → email email → rollno Select the correct option:
Ans. (c) The schema is in 3NF but not in BCNF Explanation: The following are the candidate keys for the given schema:
Given, there is a functional dependency: email → rollno, but email is not a super key. We can say that this schema is not in BCNF. Also, all the attribute rollno, courseid, and email all are the prime attributes and there is no functional dependency from non-prime to non-prime attribute. We can say that the schema is in 3NF. Hence, option (c) is the correct answer. Q. 10 Consider a relationship R(a, b, c, d) where a, b, c, and d are simple single valued attributes. The following functional dependency exist among these attributes a → c and b → d. Identify the normal form of the relationship.
Ans. (a). Explanation: Given Function Dependencies are a → c and b → d and 'ab' will be the candidate key. Both the dependencies are the simple example of partial dependencies where non-prime attributes (c and d) are dependent on the subset of the candidate key. Which clearly violates the condition of 2 NF. Hence, (a) is the correct answer. Q. 11 The relationship table obtained from the ER diagram will always be in
Ans. (a) 1 NF Explanation: The table obtained from ER diagram will always be in 1NF and to eliminate redundant data, we can normalize the table. Q. 12 Data that enhances the database's usability and performance are referred to as
Ans. (b) Indexes Explanation: Indexes are use to increase tha database performance and searching ability. Q. 13 B + Trees are regarded as BALANCED because
Ans. (a) B + Trees are regarded as BALANCED because all of the pathways from the root to the leaf nodes are the same length. Explanation: The length of the paths from the root to all leaves are always equal because it grows in a bottom-up fashion. Hence, (a) is the correct answer. Q. 14 What is the main reason B+ trees are preferred over binary search trees when indexing database relations?
Ans. (d) Block-based data transmission from drives is used Explanation: B+ tree are Balanced tree and block-based data transmission from drives can be easily done using B+ trees. Q. 15 Which of the subsequent statements is true?
Ans. (b) On B+ trees, range searches are quicker Explanation: In B+ trees, each leaf node store a pointer to next leaf node which makes the range query or searching faster. Q. 16 Which of the following claims regarding the B+ tree data structure, which is used to build an index of a relational database table, is FALSE?
Ans. (b) Nodes that are not leaves have pointers to data records. Explanation: Each non-leaf nodes contain key values and pointer to its children. Whereas each leaf node contains key values, pointer to the data record and pointer to the subsequent leaf node. Hence, statement (b) is false. Q. 17 Which of the following situations could result in an unrecoverable error in a database system?
Ans. (a) A transaction reads a data object updated by an uncommitted transaction will lead to the database in unrecoverable state. Explanation: When a transaction reads a data object updated by another uncommitted transaction called dirty read and if any failure occurs, the database become unrecoverable. Q. 18 Take a look at the given schedules S1 and S2, along with the transactions T1, T2, and T3. T1: r1(X); r1(Z); w1(X); w1(Z) T2: r2(Y); r2(Z); w2(Z) T3: r3(Y); r3(X); w3(Y)
Out of the following schedule-related claims, which one is TRUE?
Ans. (a) Only S1 is Conflict Serializable. Explanation: Schedule s1 is conflict Serializable because we can obtain a serial schedule by swapping the non-conflicting instruction of T1, T2 and T3 and the order will be T2 -> T3 -> T1. Whereas, it is not possible in Schedule S2. T1 is dependent on T2 and T2 is dependent on T1. As there is dependency cycle, we can say that the S2 is not conflict serializable. Hence, (a) is the correct answer. Q. 19 Which of the following is not a part of ACID properties of a transaction?
Ans. (d) Deadlock Prevention. Explanation: Atomicity, Consistency, Isolation and Durability are called the ACID property. Deadlock-prevention is not a part of it. Q. 20 Which of the subsequent claims is FALSE?
Ans. (c) Cascading rollback is a problem with Time-Stamp Protocols, but it is not with 2-Phase Locking Protocol Explanation: Two-phase locking suffers from cascading roll-backs and does not ensure deadlock freedom.
Next TopicWhat is a Login Script
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








