| |

What is Stable Diffusion?Stable diffusion is a 2022 latent text-to-image diffusion model. LDMs work by repeatedly lowering the noise in an image's latent space and then turning this representation into a visual representation. The text-to-image production process in stable dissemination can be separated into four stages using a model that integrates several neural networks. Here's a rundown:
Stable diffusion may create a wide variety of artistic forms, such as photographic landscapes, portraits, and abstract art. The method has been used in a variety of applications, including image generation for scientific study, digital art creation, and video game development. Game makers, for example, can use the model to produce game assets like characters and game scenes from text descriptions. E-commerce sites can also enter a product description to build a product design. Stable Diffusion's principal role is to create comprehensive photographs based on textual descriptions, but it may also be used for other tasks such as in painting, outpointing, and making image-to-image translations driven by text prompts. Its measurements, model card, and code are all open to the public. Stable Diffusion was established by Stability AI in collaboration with numerous university researchers and non-profit organizations. To execute stable diffusion, a GPU with a minimum of 6.9GB of video memory is recommended. This makes it simpler to use than prior text-to-image models such as DALL-E and Midjourney, which are patented and only available through cloud services. What is the process of stable diffusion?Stable diffusion works by applying the diffusion method to an image iteratively. The diffusion coefficient is computed at each iteration based on local picture properties such as variations and edges. This coefficient affects the diffusion's strength and direction, allowing the technique to change the smoothing effect throughout different portions of the image adaptively. The diffusion process re-assigns values for pixels based on local information. The technique lowers noise by distributing pixel values in quiet regions while maintaining crisp transitions and edges. This selective smoothing aids in the preservation of image details and the avoidance of blurring or the loss of crucial features. The following is a summary of the procedure:Stable diffusion begins by understanding and reading the request when a user enters the description in natural language. The text is analysed with artificial intelligence, and relevant knowledge is extracted with the goal of generating the desired image. Diffusion Model: Stable Diffusion uses a model of diffusion that has been developed to remove Gaussian noise from fuzzy photos. The broadcast method is designed to create images from ground level up, starting with an initially noisy and blurred initial image. The model gradually improves the image through iterative refinement until it produces a clear and sharp result that corresponds to the user's intended output. Continuous learning: As user involvement increases and text descriptions are sent to a stable diffusion, the machine learning algorithm continuously learns and improves its outputs. Stable diffusion is able to generate pictures that are increasingly exact and lifelike because of this constant learning process. Image generation: After understanding the text and performing the diffusion approach, Stable Diffusion generates an image based on the information provided and the knowledge obtained from its training. In some cases, artificial intelligence can generate several images representing various views or perceptions of the specified description. Editing pre-existing images: In addition to creating images from scratch, Stable Diffusion may edit existing ones based on user input. This includes operations like adding or removing items, changing colors, and adjusting other aspects of the image. How to use stable diffusion?Stable diffusion has several applications and settings. Here are three popular strategies for properly utilizing stable diffusion: 1) Use cloud-stabilized diffusion.Cloud-based services make it simple to use stable diffusion. Many organizations offer stable diffusion services over the cloud, allowing customers to create artwork based on their needs. These services normally entail uploading the input photograph and choosing an appropriate artistic style. The service then applies stable diffusion to generate the final image, which may be saved or shared online. There are various benefits to using cloud-based stable diffusion. First and foremost, it is frequently faster than performing the algorithm locally. Second, these services are capable of handling massive processing, culminating in the rapid output of high-quality photos. Finally, using stable diffusion on the cloud is frequently more cost-effective because users just pay for what resources they use, thereby minimizing expenses. 2) Use localized stable diffusion.An alternative option is to run stable diffusion on the machine you're using. Stable diffusion software must be installed on your device for this to work. After installing the app, you can use it to create artwork using stable diffusion. Performing stable diffusion locally has a number of advantages. For starters, it gives you more control throughout the process, allowing you to tailor the algorithm to your individual needs. Second, running stable diffusion on a local machine permits you to create artwork without requiring a connection to the internet, which might be useful when access to the internet is limited or unavailable. 3) Use online stable diffusion.Many internet platforms offer stable diffusion as an additional service, allowing customers to take advantage of its capabilities. These websites allow users to upload photographs, which undergo processing using stable diffusion to create numerous artistic styles. When the method is finished, the resultant image is able to be purchased or shared. Using stable diffusion online has various advantages. For starters, it is frequently provided for free or at a low cost, making it accessible for all users. Second, using stable diffusion via the internet is simple and does not require technical knowledge. Finally, many online sites provide a vast choice of artistic styles from which to choose, allowing users to investigate and experiment with various techniques and aesthetics. How to Run Free, Stable Diffusion OnlineThere are various ways to do this. In this article, we will explain the ideal way for novices to begin their adventure with the stable dissemination model. One of the most effective ways to utilize stable diffusion for yourself is to use the Fotor AI picture generator. It is a platform built on the stable diffusion model that is capable of producing images using natural language descriptions, often known as "prompts." The most impressive aspect of AI text-to-image generator is that it is ideal for beginners. No editing and design skills are required; simply enter the text of your intended artworks in as much detail as possible, and you may easily and quickly produce magnificent artwork such as AI anime characters, AI avatars, AI backgrounds, and more through the use of artificial intelligence. The Diffusion modelsDiffusion models are generative. They are used for producing data that is similar to the information on which they were trained. Fundamentally, diffusion models work in such a way that they "destroy" learned data by iteratively introducing Gaussian noise, and then they learn how to restore the data by removing the noise. 
The forward diffusion process introduces more and more noise into the image. As a result, the image is captured, and noise from it is added in different temporal increments until the entire image is just noise at point T. Backward diffusing is a reversal of the forward diffusion process in which noise from temporal phase t is iteratively eliminated in temporal step t-1. This process is continued until all noise has been eliminated from the image using the U-Net convolutional neural network, which has been trained to figure out the amount of noise on the image in addition to its other uses in machine deep learning. 
The image depicts iterative noise addition from left to right and iterative noise removal from right to left. U-Net is the most commonly used method for estimation and noise removal. It's fascinating that the neural network's topology is similar to the letter U, so that's how it acquired its name. U-Net is a fully connected convolutional neural network, or CNN, that is highly effective for image processing. U-Net distinguishes itself by its capacity to take a snapshot as a starting point, find a low-dimensional version of that image through decreasing the sampling, making it more appropriate for handling and finding its significant attributes, and then revert the picture to its original dimension through raising the sampling. 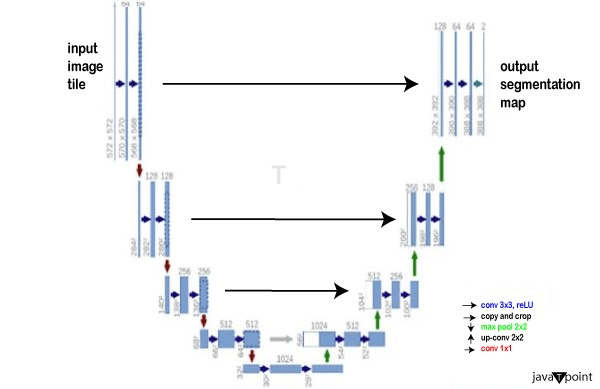
In greater detail, removing the background noise, or transitioning from arbitrary temporal step t to chronological step t-1, when t is the amount of the difference between T0 (the image without noise) and the final number TMAX (total noise), occurs as follows: The input is the image in chronological step t, and in that temporal step there is specific noise on the image. 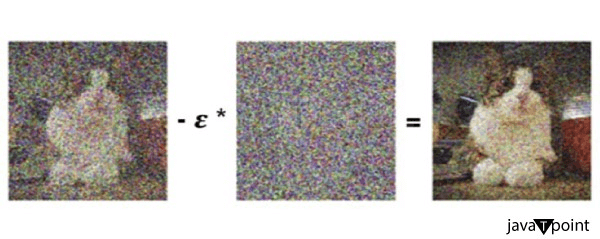
TextApplying text to this model is accomplished by "embedding" words with speech transformers, which indicate that amounts (tokens) are included in the phrases before the resulting representation of what is written is uploaded to the source data (the image) in U-Net, where it travels through all the layers of the U-Net network of neural networks and transforms alongside the image. This is done starting with the first temporal iteration, and the identical text is added to each subsequent iteration after the first noise estimation. We may say that the text "serves as a guideline" for generating the image, beginning with the first iteration in which there is no noise and progressing through the full iterative technique. PossibilitiesGiven the mode's complex construction, a reliable diffusion may produce an image "from scratch" by using a message box that specifies which elements should be displayed or excluded from the output. Using the text prompt, you can easily add new elements to an existing image. Finally, on the web page huggingface.co, there is an area where you can experiment with a stable dispersion model. Here are the outcomes when the prompt is filled with the wording "A pikachu exquisite meal with a view of the Eiffel Tower": 
Over the last few months, stable diffusion has received a lot of attention. The reasons for this are that the original source code is available to everyone, reliable distribution does not own any rights to generated photos, and it also allows individuals to be creative, as evidenced by the enormous number of fantastic published images created using this approach. We can confidently assert that generative models are generated and enhanced on a weekly basis, and it will be fascinating to follow their evolution in the future. What is the purpose of stable diffusion?The stable diffusion method is used for creating images according to text prompts and to modify existing images through the inpainting and outpainting processes. It can, for example, generate a whole image from a detailed written description or replace a small section of an existing image. Can you spot an AI-generated image?Stable Diffusion can produce realistic photos that are difficult to distinguish from the real item, as well as visuals that are difficult to distinguish from drawn by hand or painted artwork. a number of prompts and other conditions, it can also produce photos that are blatantly phoney. Look for AI-generated art in the fingers, as stable dissemination and other models struggle in that area. If the subject of a photograph is blatantly covering their hands, it's a good bet that someone did some creative prompt engineering to circumvent the AI model's flaws. However, keep in mind that AI models evolve at a breakneck pace, so these flaws are likely to be temporary. Stable Diffusion Controversies and ProblemsStable diffusion images can hypothetically be used for almost any purpose; however, there are some dangers associated with AI-generated content. Because AI picture synthesis must learn about items from someplace, its programmers have scoured the internet for art accompanied by metadata. They did it without the authorization of the creators of the source art, which poses questions of copyright. This is especially problematic because stable diffusion does not construct its images from scratch; instead, it assembles them from previously analyzed images. So, whether they've provided permission or not, it uses the art of others in both learning and creating. Sites like DeviantArt have just averted a major exodus by allowing users to opt out of allowing AI systems to use their artwork for training. The problem of copyrighting works made in part by AI is similarly murky, the copyright applications involving works including AI-generated components have been denied. Nonetheless, as AI-driven image generation grows more common, it affects the livelihoods of conventional artists, who risk losing employment to this cheaper, "easier" alternative. Install stable diffusion.Instead of relying on the various websites that utilize stabilized diffusion for a model, you may download the programme on your PC. However, be cautioned that establishing the programme is difficult and requires multiple exact procedures. The good thing is that once completed, you are able to revisit it whenever and however frequently you choose. Whenever you begin, ensure that your PC fulfils the following minimum requirements: Windows 10 or 11, as well as an independent NVIDIA video card with 4GB or more of VRAM. The DirectX Diagnostic Tool can be used to determine the name and model of your visual card as well as the quantity of VRAM. To open the Run box, use the Windows key plus R. Enter dxdiag into the open field. Click the Display tab in the DirectX Diagnostic Tool window to view the identification of your card and the amount of VRAM it has. If your card is valid, proceed to the following steps:
Peek into the Stable Diffusion app and you'll find a slew of other options, including ones to submit a picture to generate a version of it, scale and otherwise modify an image, and access various extensions. Characteristics and Advantages of Stable DiffusionStable Diffusion's software code is freely accessible, permitting anyone with access to create solutions from the core base. This allows the community a lot of leeway in improving and growing artificial intelligence. Furthermore, because Stable Diffusion is a freely available project, programmers can train and customise it to their individual needs and projects. Stable diffusion can alter existing photos in addition to generating images from text requests. Users can upload an image and request the inclusion or removal of particular objects, a method known as Image to Image, in which users can generate new images from current photographs by modifying them or adding specific parts as requested. ConclusionIn this article, we discussed what stable diffusion is, how it works, and how to apply it. There are four ways to operate Stable Diffusion, including a free one using AI art creator. Practice with stable diffusion to see how it might enhance your digital visuals. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








